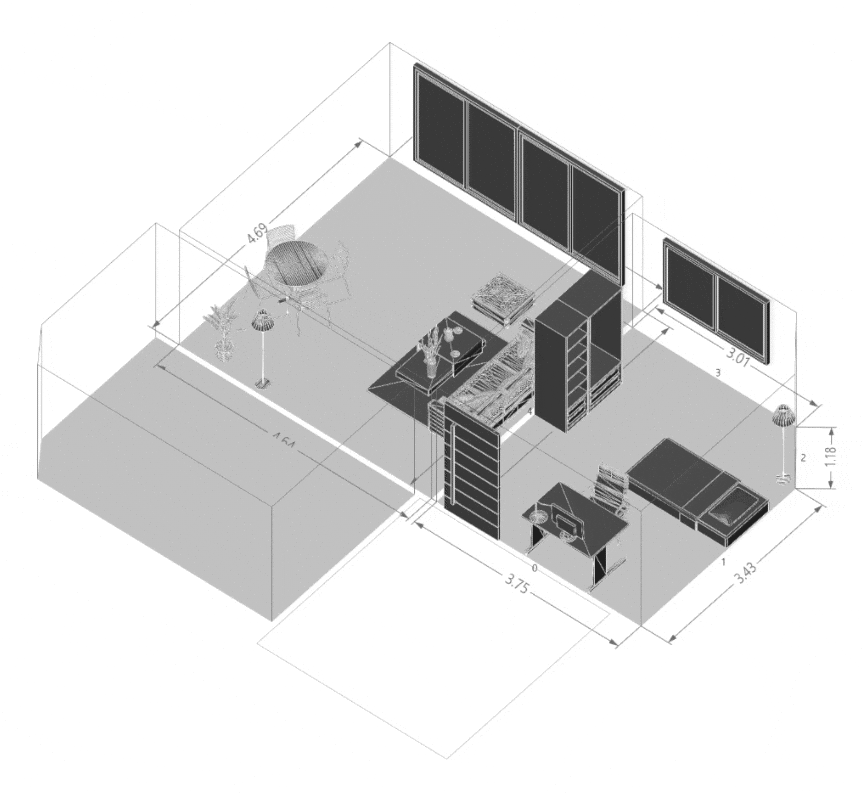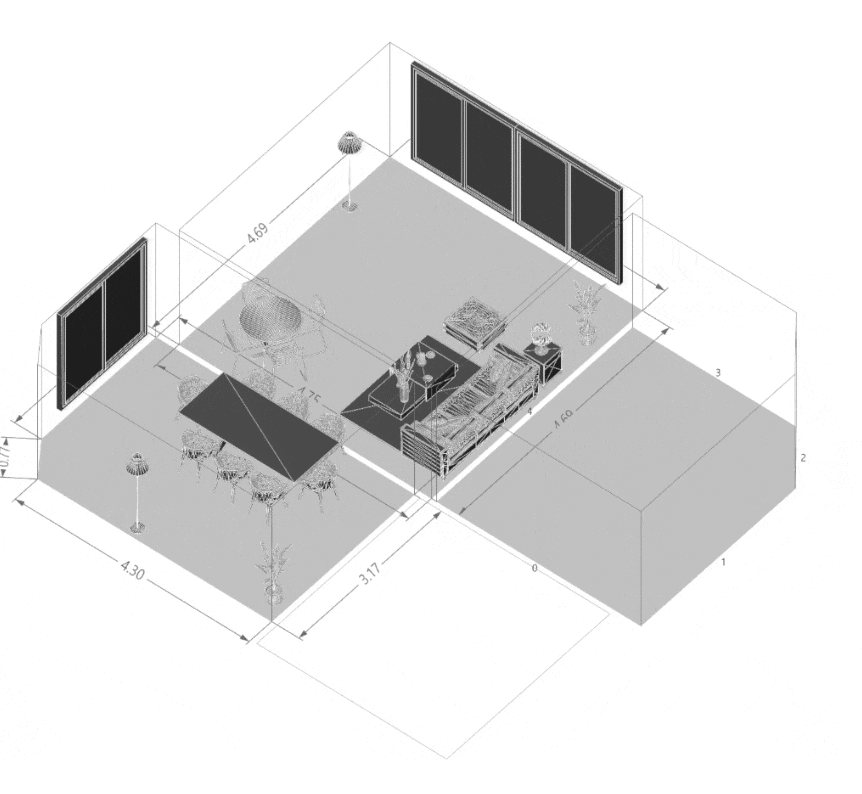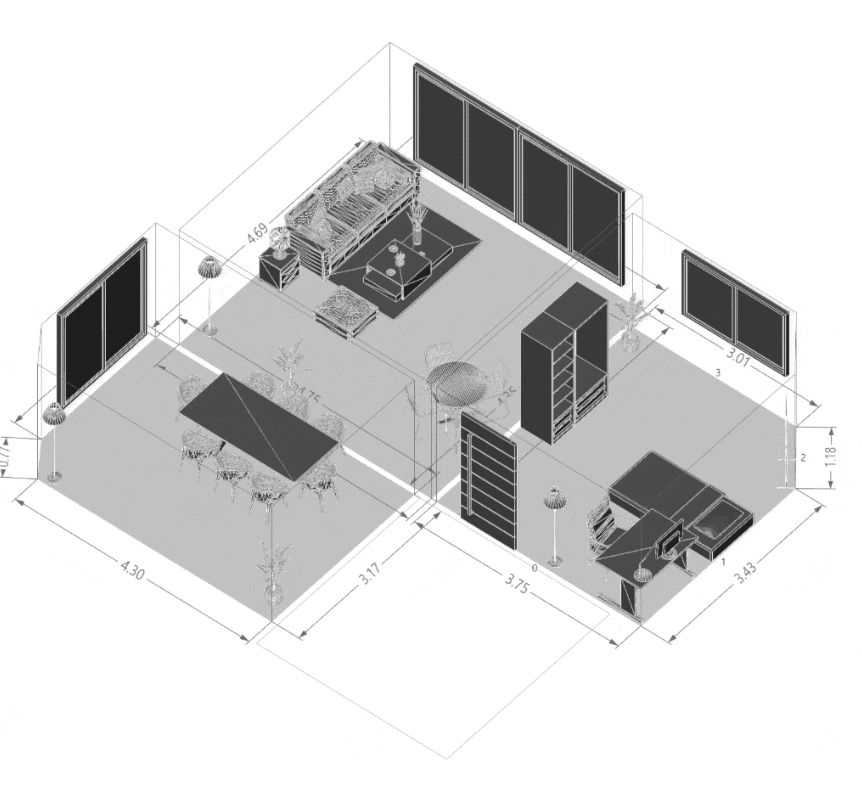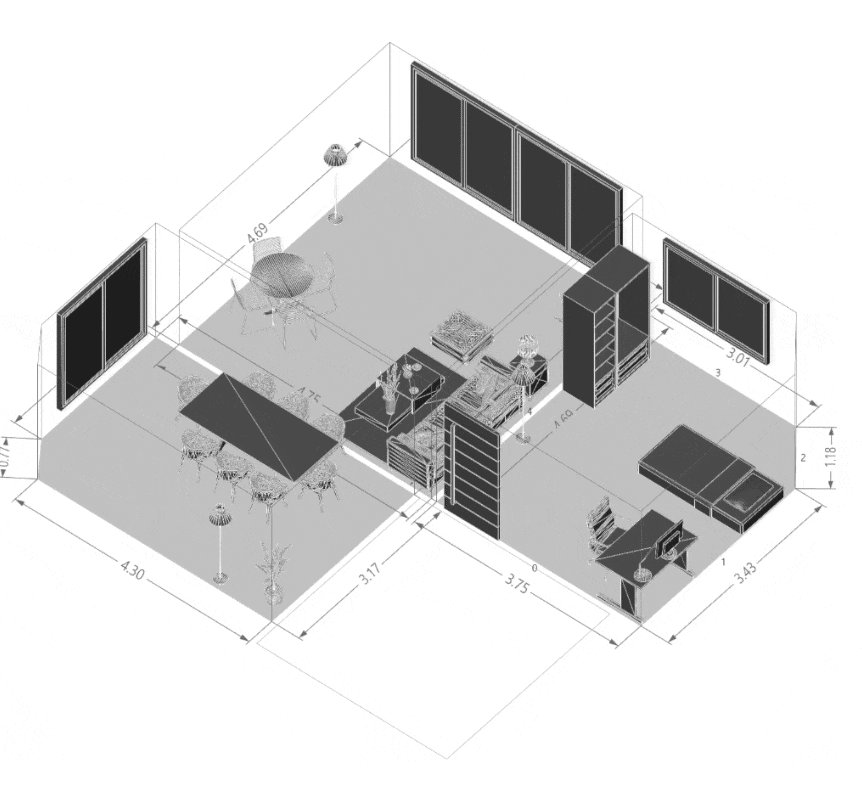
Quantifying Architectural Design
02/23/2025, thsu-swk
1.
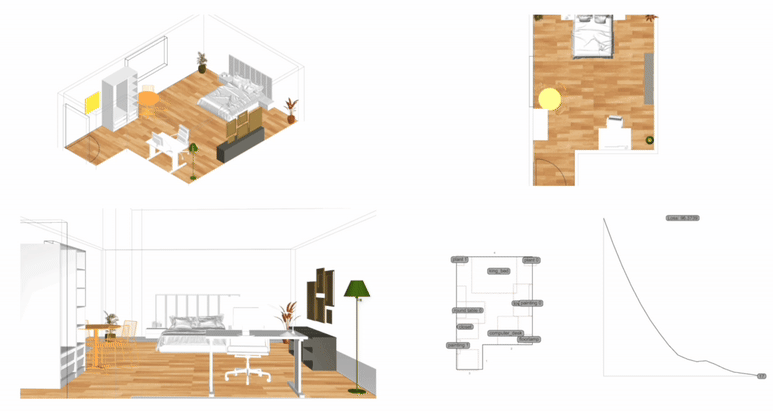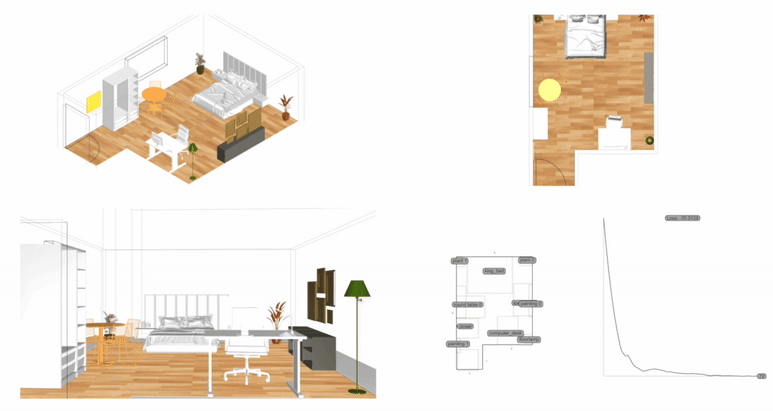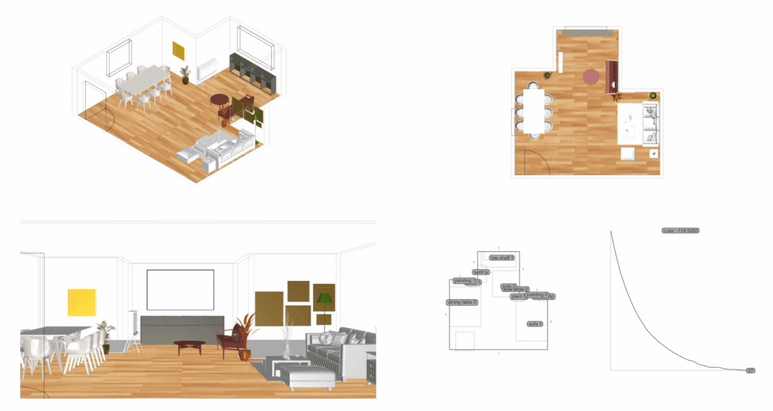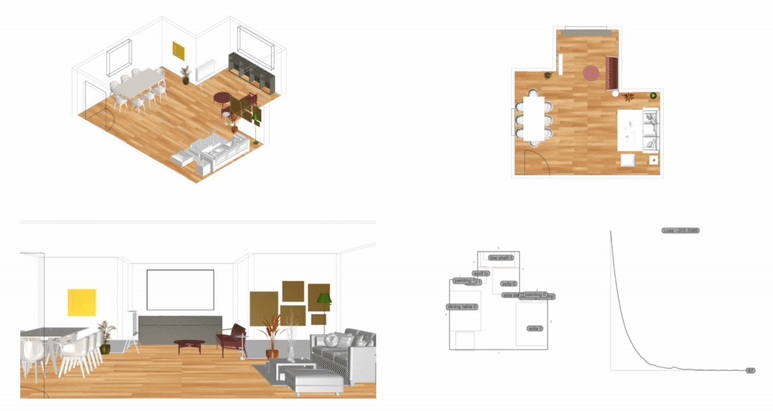
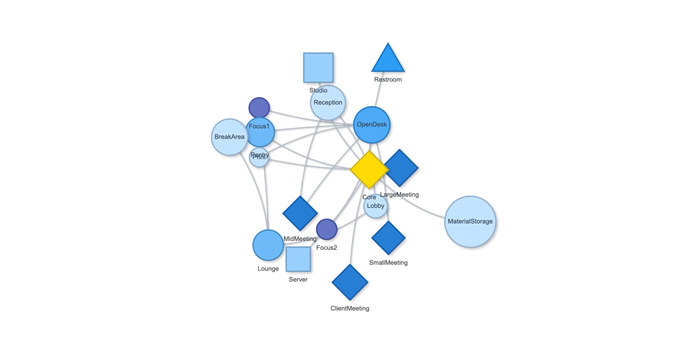
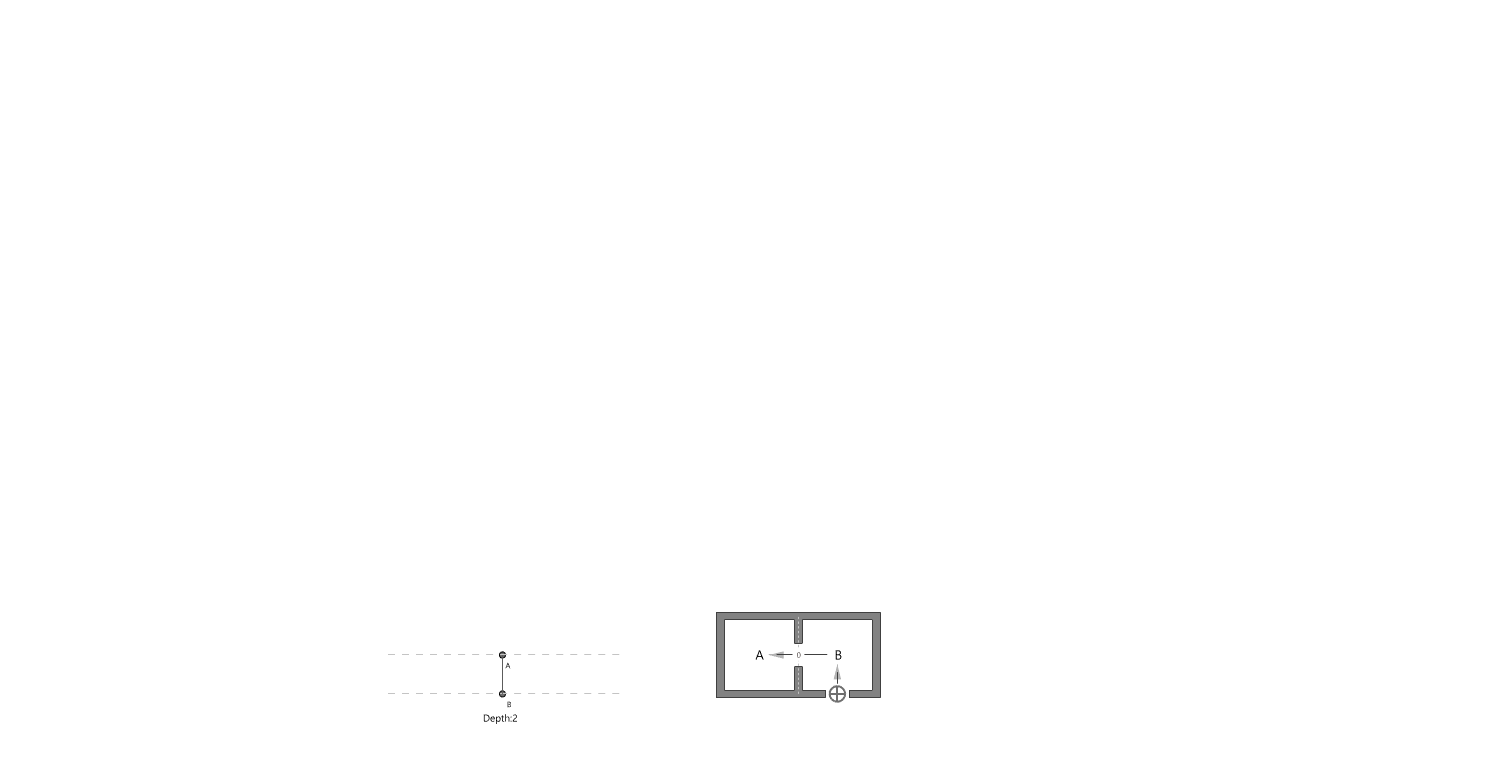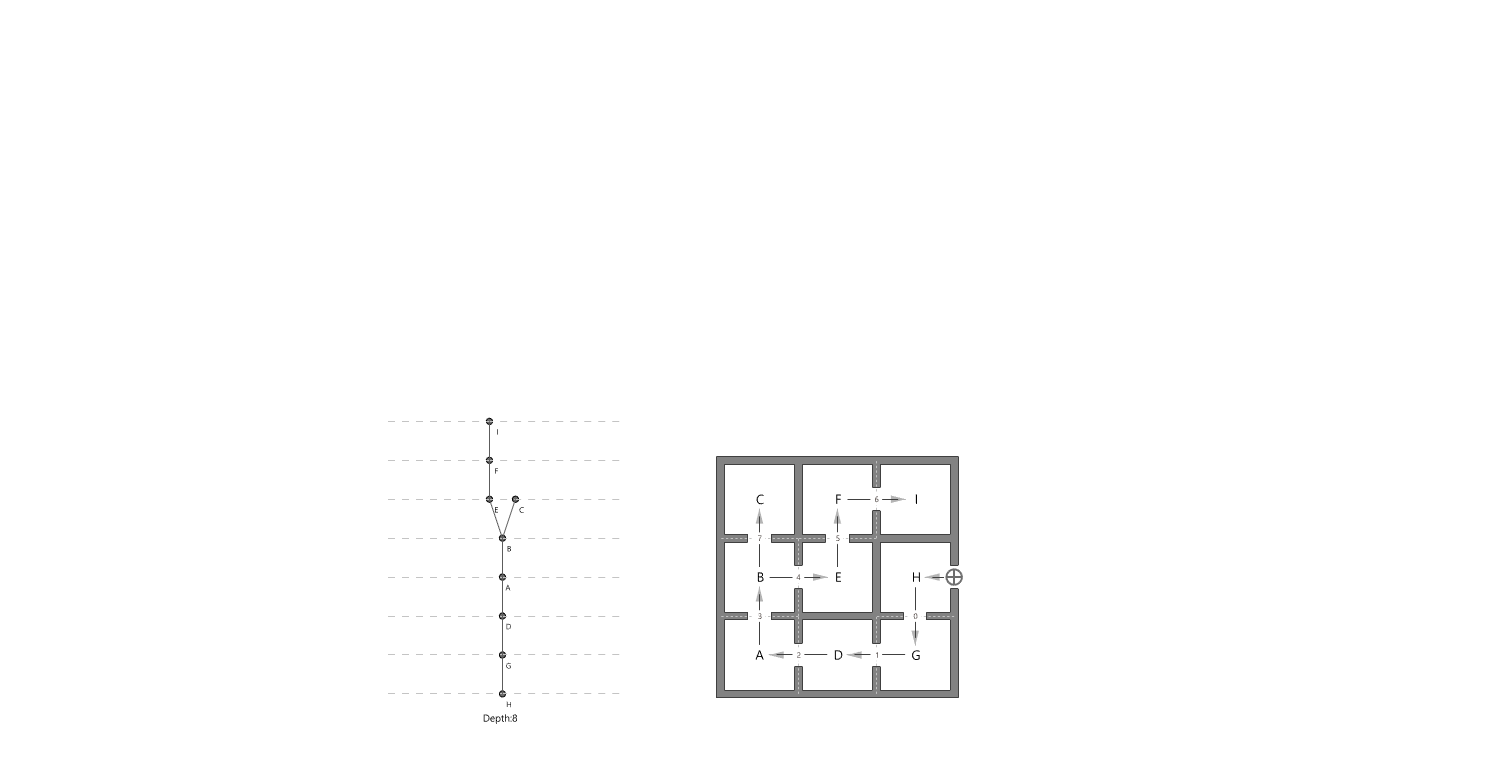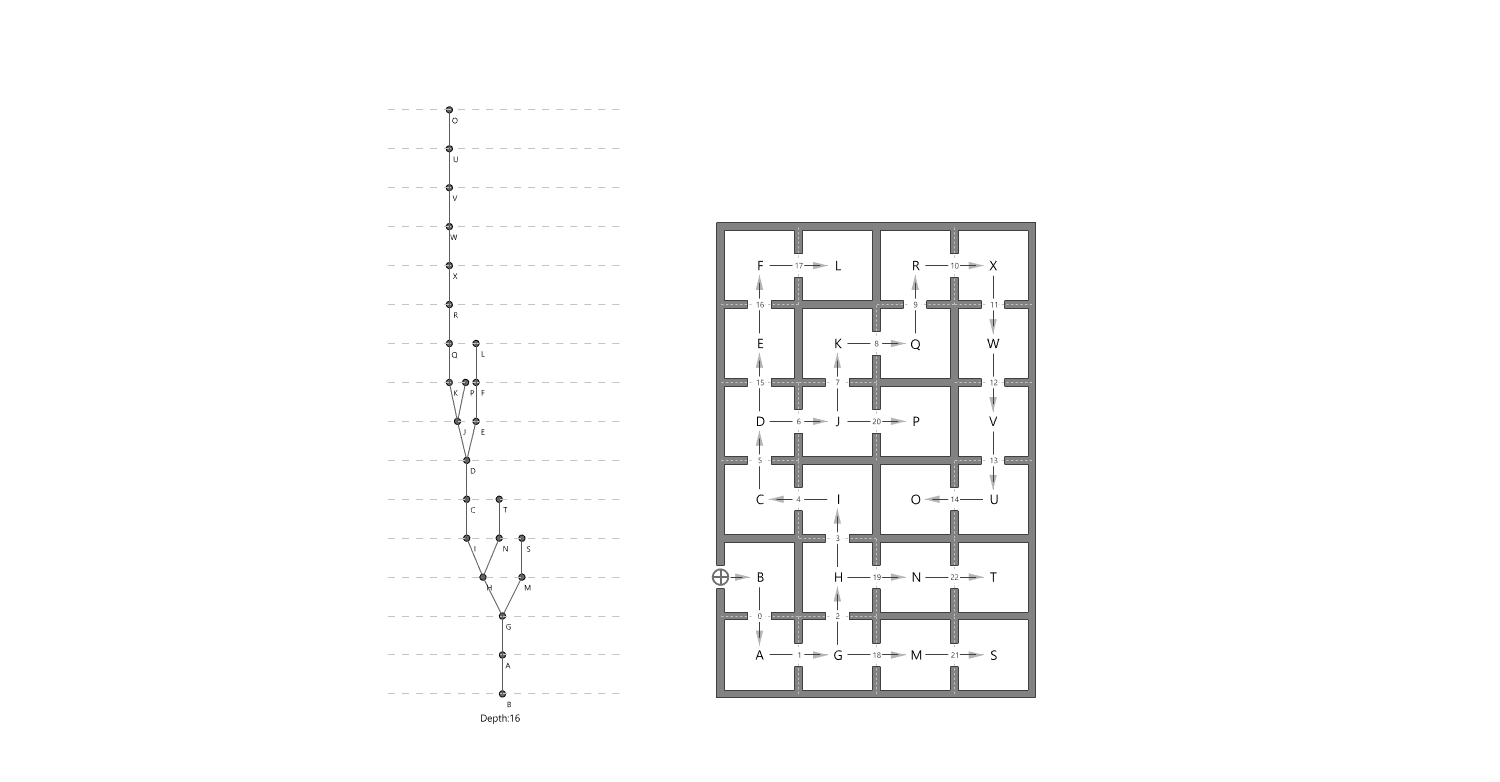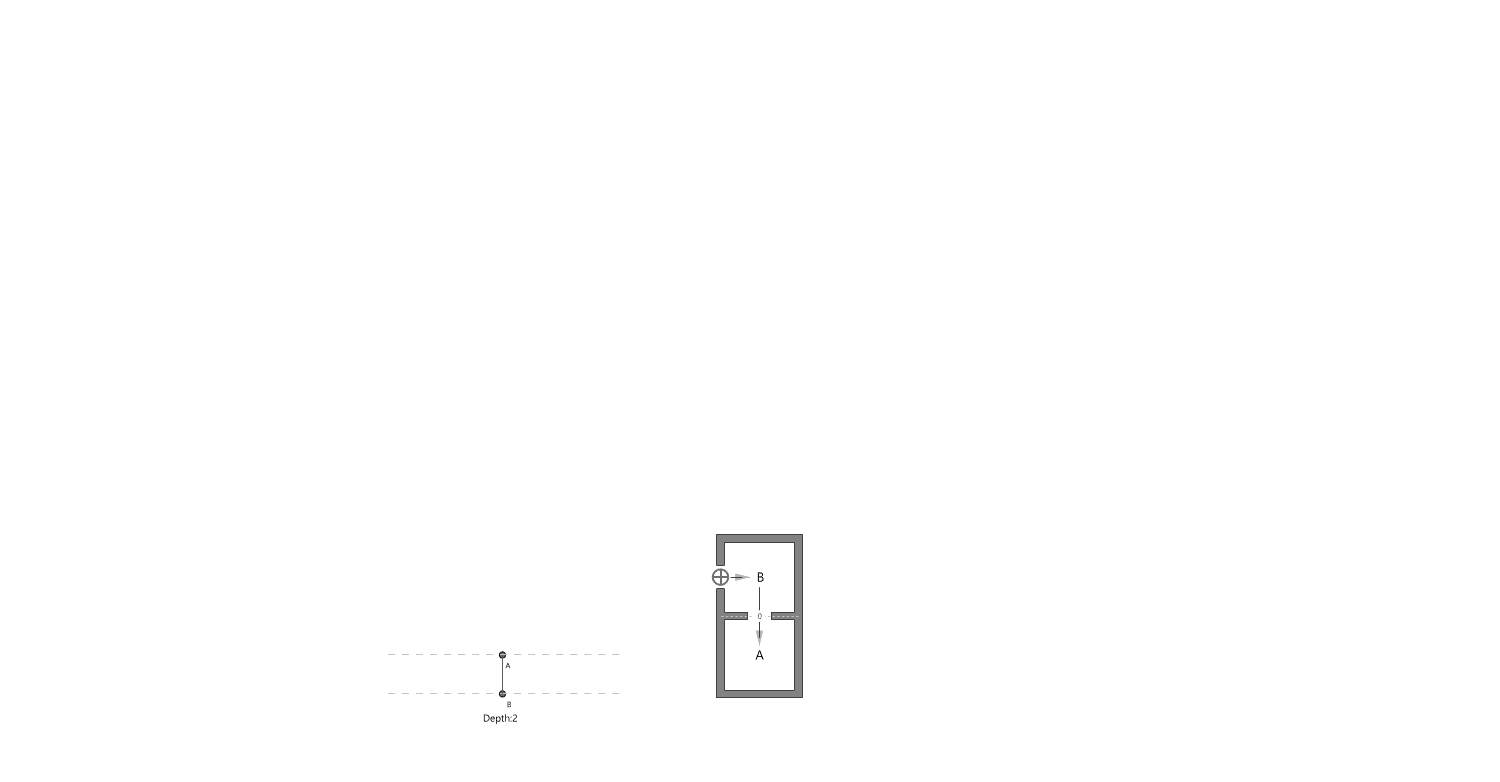
Measurement: Why It Matters 공간이나 건축에서 ‘측정하고 계산한다’는 말은 단순히 도면 위에 치수를 적어두는 수준을 넘어선다. 예를 들어, 건축가는 건물 벽의 두께나 층고를 재는 일뿐 아니라, 사람들이 그 공간에서 얼마나 오래 머무는지, 어떤 방향으로 주로 이동하는지까지도 살핀다. 결국 측정이라는 과정은, 디자인 문제를 종합적으로 이해하기 위한 중요한 단서가 된다. 물론 디자인의 모든 것을 숫자로만 파악할 수 있는 것은 아니다. 하지만 제임스 빈센트가 강조했듯이, 측정이라는 행위 자체가 우리가 놓치던 세부를 더 깊이 들여다보게 만든다. 예컨대 “도시가 커질수록 혁신성이 올라간다”는 말이, 정량적 통계로 확인될 때 그 의미가 더욱 명확해진다는 뜻이다. 다시 말해, 디자인에서의 측정이란 감에 의존하던 의사 결정을 좀 더 분명한 근거 위에 올려놓는 데 기여한다. 2. The History of Measurement Leonardo da Vinci’s Vitruvian Man 옛 시절을 떠올려 보자. 고대 이집트에서는 팔꿈치 끝부터 손가락 끝까지의 길이를 기준으로 건물을 지었고, 중국은 ‘척’이라는 단위를 도입해 만리장성 같은 대규모 공사를 보다 정확히 진행할 수 있었다. 르네상스 시대로 건너가면, 레오나르도 다빈치의 비트루비안 인간을 통해 예술과 수학의 결합이 두드러졌고, 갈릴레오 갈릴레이가 “측정할 수 없는 것은 측정 가능하게 하라”고 말했던 일화에서 보듯, 자연 현상을 수치로 정밀하게 규정하는 시도가 자리 잡았다. 그리고 지금의 디지털 시대에 이르면, 나노미터 단위의 계측이 가능해지고, 컴퓨터와 AI 기술이 방대한 데이터를 순식간에 분석해 준다. 옛 시절 예술가들이 감에 의존해 섬세한 작업을 했다면, 이제는 3D 프린터로 1mm 오차도 없는 구조물을 만드는 시대가 됐다. 도시나 건축에서 측정과 계산이 얼마나 중요한지를 보여주는 예라고 할 수 있다. 3. The Meaning of Measurement 영국 물리학자인 윌리엄 톰슨(케빈 경)은 “무언가를 숫자로 표현할 수 있다면, 어느 정도 이해했다는 의미이고, 그렇지 못하면 아직 미흡한 것”이라고 지적했다. 이런 맥락에서 보면, 측정은 곧 이해의 폭과 깊이를 넓혀주는 도구이자, 우리가 얻은 지식에 신뢰도를 부여하는 근거가 된다. 건축만 보더라도, 구조적 안전을 위해 하중을 계산하고, 재료 물성을 파악하는 일이 우선시된다. 에너지 절감을 목표로 일조량을 예측하거나 소음을 수치화하는 등의 과정은 설계 단계에서 최적의 해법을 찾는 데 도움이 된다. 도시에 관한 연구에서도, 물리학자 제프리 웨스트가 저서 스케일에서 지적했듯이, 인구가 늘어남에 따라 특허나 혁신이 증가하는 비율이 단순한 추세가 아니라 실제 통계로 확인될 때, 도시 디자인은 더 뚜렷한 방향성을 갖게 된다. 하지만 무엇을 측정하고 어떤 지표를 믿느냐에 따라 결과 해석이 크게 달라진다. 맥나마라의 오류처럼, 엉뚱한 지표를 맹신하면 본래 달성해야 할 목표가 흐려지게 된다. 특히 도시나 건축은 인간의 삶과 맞닿아 있는 영역인 만큼, 숫자로 환원하기 어려운 가치—이를테면 공간이 주는 정서적 만족감이나 장소성—도 다뤄야 한다. 바츠라프 스밀이 “숫자가 실제로 말해주는 바를 알아야 한다”고 경고한 것도 같은 이유다. 숫자만 보지 말고, 그 뒤에 깔린 맥락을 함께 들여다보라는 의미다. 4. The “Unmeasurable” 디자인에서 수치화하기 어려운 부분의 대표적인 예로는 미적 감각이 있다. 아름다움, 분위기, 사용자 만족, 사회적 연결감 등은 한계가 뚜렷하다. 다만, Birkhoff의 미적 척도미적 값 M = 질서도(O) / 복잡도(C)처럼 질서와 복잡도의 비율을 통해 시도해보려는 연구가 있기는 하다. 또, 설문 조사나 피드백 데이터를 토대로 만족도를 수치화하려는 방법도 나오지만, 여전히 질적 맥락과 현장 경험은 온전히 숫자로 담기 힘들다. Informational Aesthetics Measures 디자인 칼럼니스트 질리언 테드가 “숫자에만 의존하면 정작 주변 맥락을 놓칠 수 있다”는 경고를 남긴 것도 같은 맥락이다. 결국 ‘숫자와 인간’을 잇는 통찰이 필요하다는 뜻이다. 한편, 건축이론가 K. Michael Hays는 고대 피타고라스·플라톤 철학의 비례 개념에서 비롯된 건축이 이후 디지털·알고리즘 설계까지 이어져 왔음을 지적하면서도, 건축적 경험을 완전히 수치로 표현하는 것은 불가능하다고 본다. 면적이나 비용 등은 환산되더라도, “왜 이 공간이 이렇게 배치돼야 하느냐”에 대한 답은 단순 숫자만으로는 충분치 않다는 것이다. 결국 디자이너가 숫자와 함께 ‘숫자로 묘사되지 않는 요소’를 고민해야 비로소 의미 있는 공간이 나온다. 5. Algorithmic Methods to Measure, Analyze, and Compute Space 최근에는 건축·도시 설계에 그래프 이론과 시뮬레이션, 최적화 기법을 접목해 공간 분석을 정교화하는 사례가 증가했다. 예컨대 건축 평면을 노드와 엣지로 구성해 방과 방 사이의 깊이나 접근성을 계산하거나, 유전 알고리즘으로 병원 평면이나 사무실 배치를 자동화하려는 시도도 있다. 또, 도시 차원의 교통 흐름이나 보행자 동선을 시뮬레이션해 최적 해법을 찾는 연구가 활발하다. 이처럼 알고리즘과 계산을 통해 공간 성능을 수치화하면, 디자이너는 그 수치를 바탕으로 더 합리적이고 창의적인 결정을 내릴 수 있다. Spatial Networks 건축 평면이나 도시 거리망을 노드와 엣지로 표현하여, 각 공간(또는 교차로) 간의 연결성을 평가한다. 예를 들어, 방과 방을 연결하는 문을 엣지로 삼으면 방들의 접근성을 최단경로 알고리즘(Dijkstra, A* 등)으로 계산할 수 있다. Spatial networks Justified Permeability Graph (JPG) 건축물 내부 공간의 깊이(depth)를 측정할 때, 주 출입구 등 특정 공간을 루트로 하여 층위적으로 배치한 정당화 그래프를 만든다. 루트로부터 얼마나 많은 단계를 거쳐야 도달하는지(=방의 깊이)를 보면 개방적·중심적 공간과 고립된 공간을 파악할 수 있다. Justified Permeability Graph (JPG) Visibility Graph Analysis (VGA) 공간을 촘촘히 분할하고, 서로 가시한 점들끼리 연결하여 시야적 연결망을 만든다. 이를 통해 어디가 가장 시야적으로 개방된 지점인지, 사람들이 많이 머무를 가능성이 높은 구역은 어디인지 예측 가능하다. Axial Line Analysis 실내나 도시를 사람이 실제로 이동할 수 있는 가장 긴 직선(축선)들로 나눈 뒤, 축선끼리 만나는 교차점을 엣지로 연결한 그래프를 만든다. 이때 통합도(Integration), 평균 심도(Mean Depth) 등의 지표를 산출해, 동선의 중심성이나 사적 공간 여부를 추정할 수 있다. Genetic Algorithm (GA) 건축 평면 배치나 도시 용도 배분 등에서, 여러 요구조건(면적, 인접성, 일조 등)을 적합도 함수로 설정하여 무작위 해를 진화시키는 방식이다. 세대를 거듭하며 최적 평면 혹은 배치안에 가까워진다. Reinforcement Learning (RL) 보행자나 차량을 에이전트로 삼고, 원하는 목표(빠른 이동, 충돌 최소화 등)에 대한 보상 함수를 두어 스스로 최적 경로를 학습하게 한다. 대형 건물이나 도시 교차로에서 군중 흐름이나 교통 흐름을 시뮬레이션하는 데 유용하다. 6. Using LLM Multimodality for Quantification 인공지능이 발전하면서, LLM(대형 언어 모델)이 건축 도면이나 디자인 이미지를 분석해 정성적 요소까지 어느 정도 수치화하려는 노력도 보인다. 예컨대 건축 디자인 이미지를 입력하고, 텍스트로 된 요구사항을 대조한 뒤 ‘디자인 적합성’을 점수로 제시하는 식이다. 건축 도면끼리 비교해 건축법 준수 여부나 창문 활용 비율을 자동으로 파악해주는 프로그램도 시범 운영되고 있다. 이 과정을 통해 동선 길이, 채광 면적, 시설 접근성 등을 정리한 후, 디자이너가 “이 디자인이 제일 적절해 보인다”는 판단을 내릴 수 있게 도와주는 것이다. 7. A Real-World Example: Automating Office Layout Automating Office Layout 사무실 평면 설계를 자동화하는 과정은 크게 세 단계로 나눌 수 있다. 먼저, LLM(Large Language Model)이 사용자 요구사항을 분석하고, 이를 컴퓨터가 이해할 수 있는 형식으로 바꿔준다. 다음으로, 파라메트릭 모델과 최적화 알고리즘이 수십·수백 가지 평면 시안을 만들어 각종 지표(접근성·에너지 효율·동선 길이 등)로 평가한다. 마지막으로, LLM이 그 결과를 자연어로 요약·해석해 제안한다. 이때 LLM은 GPT-4 등과 같이 대규모 텍스트 데이터로 학습된 모델을 뜻하며, 사용자의 “50인 규모 사무실에 회의실 2개, 로비 조망은 충분해야 함” 같은 지시를 받아 건축 알고리즘 툴이 이해할 수 있는 스크립트를 자동 생성하거나, 코드 수정 방안을 안내하기도 한다. Zoning diagram for office layout by architect 이 과정을 예로 들어 보자. 과거였다면, 건축가는 일일이 버블 다이어그램을 그리며 “부서를 어디에 둘지, 창문은 누가 우선 사용하게 할지”를 반복적으로 조정했다. 하지만 LLM으로 “로비에 조망을 최대한 확보하고, 협업이 잦은 부서는 서로 5m 이내로 붙여달라”라는 식의 요구사항을 파라메트릭 모델로 직결할 수 있다. 파라메트릭 모델은 기둥이나 벽, 창문 위치 같은 기본 정보를 토대로 rectangle decomposition, bin-packing 알고리즘 등을 활용해 다양한 평면 설계안을 만들어 낸다. 그 안들이 각종 지표(인접성, 협업 부서 간 거리, 창문 활용 비율 등)로 자동 평가되면, 최적화 알고리즘은 점수가 높은 상위안을 추려낸다. LLM-based office layout generation 이때 사람이 일일이 숫자 지표를 들여다보려 하면, ‘협업 부서 간 거리 평균 5m vs. 목표치 3~4m’ 같은 상세 데이터가 쏟아져 복잡해지기 쉽다. 여기서 LLM이 다시 등장한다. 최적화 결과를 받아 “이 설계안은 협업 공간 비율이 25%를 잘 충족하지만, 창문 활용도가 예정보다 높으니 에너지 효율이 조금 떨어질 수 있다” 같은 식으로, 전문가가 아닌 이도 이해하기 쉬운 문장으로 요약해준다. 예컨대 아래와 같이 브리핑할 수도 있다. “협업이 중요한 부서 간 거리는 평균 5m로, 사용자가 희망했던 3~4m 범위보다 다소 큰 편입니다. ” “에너지 사용량은 이 규모 표준 사무실 대비 10% 가량 낮게 추정됩니다. ” 만약 새로운 자료가 추가되면 LLM이 RAG(Retrieval Augmented Generation)을 이용해 문서를 재확인하고, 파라메트릭 모델에 “긴급 비상계단을 추가해야 한다”거나 “방음 성능을 더 강화해야 한다” 같은 추가 제약을 반영하라고 지시할 수도 있다. 이렇게 사람과 AI가 끊임없이 상호작용하면서, 설계자는 훨씬 짧은 시간에 다양한 대안을 탐색하고, ‘데이터에 근거한 직관’을 살려 최종 결정을 내릴 수 있게 된다. results of office layout generation 본질적으로, 측정이란 “공간을 어떻게 바라볼지”를 결정하는 도구다. 오피스라는 한정된 공간에서, 누가 어떤 우선순위를 갖고 그 공간을 점유할지를 정하는 일은 복잡한 문제이지만, LLM과 파라메트릭 모델, 최적화 알고리즘이 결합하면 그 복잡성이 한결 가벼워진다. 최종적으로 디자이너나 의사결정자가 가지는 자유도는 줄어드는 게 아니라, 오히려 “잡다한 반복 업무”에서 벗어나 프로젝트 전반의 창의적·감성적 부분에 더 집중할 수 있게 된다. 이것이 바로, ‘측정과 계산’을 바탕으로 한 사무실 레이아웃 추천 시스템이 가져다주는 효과다. 8. Conclusion 결국 측정은 “보이지 않던 것을 드러내는” 강력한 도구다. 정확한 숫자를 통해 문제를 분명히 인식하면, 직관과 감각에만 의존할 때보다 더 객관적으로 해법을 찾을 수 있다. 인공지능 시대에는 LLM과 알고리즘이 이런 측정·계산 과정을 한층 확장해, 평소 수치화하기 어려웠던 영역을 어느 정도 정량화할 수 있게 되었다. 오피스 배치 자동화 사례에서 보듯, 추상적 요구조차 LLM 덕분에 정량 파라미터가 되고, 파라메트릭 모델과 최적화 알고리즘이 수많은 대안을 생성·평가해 합리적이면서도 창의적인 결과를 제안한다. . .