Checkpointing for Kubernetes Pods
Abstract
- Kubernetes 워크플로우 시스템(Argo, Kubeflow 등)은 단계별 input/output 아티팩트 저장을 통한 checkpoint를 기본 제공하지만, 이는 주로 pod 간 데이터 전달에 초점이 맞춰져 있음
- pod 내부에서 장시간 실행되는 작업의 “중간 상태”는 별도의 checkpointing 없이는 보존되지 않아, pod 실패/재시작 시 전체 작업을 처음부터 반복해야 하는 비효율 발생
- Amazon S3 등 외부 스토리지를 활용한 pod 내부 중간 상태의 checkpointing 전략이 필요함
- 본 글에서는 S3 기반 checkpointing을 통해 pod 실패 시 마지막 저장 지점부터 작업을 재개하는 방법과, 유전 알고리즘(GA) 등 반복적 실험에서의 시간·리소스 절약 및 성공률 향상 효과를 예시와 함께 설명함
Kubernetes 작업에서 Checkpoint의 필요성
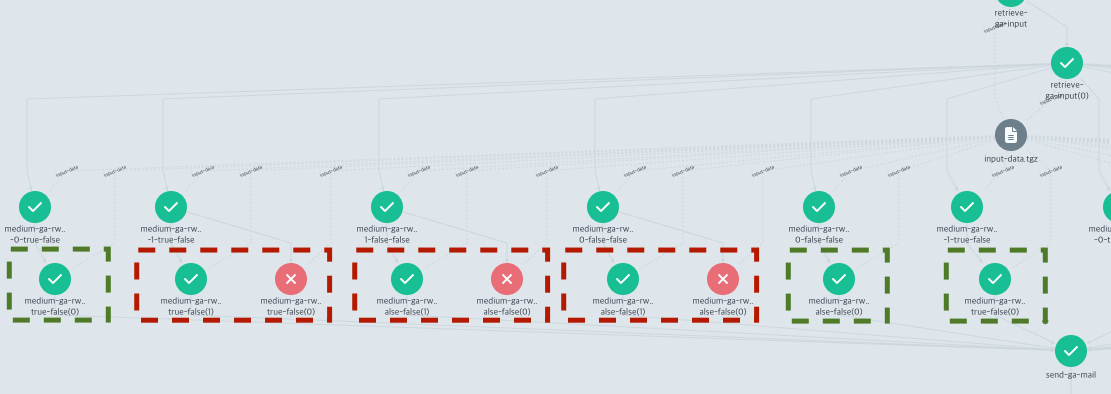
Kubernetes 환경에서 시간이 오래 걸리는 작업(예: 대규모 데이터 처리, 머신러닝 학습, 고성능 도형 시뮬레이션 등)을 수행할 때,
spot instance에서의 경쟁 상황, 메모리 부족 등으로 인해 pod가 중간에 실패하거나 재시작되는 경우가 종종 발생합니다.
Kubernetes 기반의 워크플로우 시스템(예: Argo Workflows, Kubeflow Pipelines 등)에서는 input/output artifacts를 통해 각 단계의 결과물을 저장하고, 다음 단계로 전달하는 기능이 이미 잘 지원되고 있습니다. 하지만 이러한 아티팩트 기반 저장 방식은 주로 워크플로우의 각 단계(=pod 단위) 간의 데이터 전달에 초점이 맞춰져 있습니다.
즉, pod 내부에서 오랜 시간 동안 실행되는 작업의 “중간 상태”(예: 메모리 상의 반복 연산, 실험의 진행 상황 등)는 별도의 조치 없이는 보존되지 않습니다. 만약 pod가 중간에 실패하거나 재시작된다면, 해당 pod 내에서 진행 중이던 작업은 처음부터 다시 시작될 수밖에 없습니다.
이때 아무런 조치가 없다면, 작업은 처음부터 다시 시작되어 많은 리소스와 시간을 낭비하게 됩니다. 특히 retry(재시도) 상황에서 checkpointing은 매우 유용합니다. 작업이 실패하거나 예기치 않게 중단된 후, checkpoint가 없다면 전체 과정을 처음부터 다시 반복해야 하지만, checkpoint가 있다면 마지막 저장 지점부터 빠르게 복구할 수 있습니다.
따라서, pod 내부에서의 세밀한 checkpointing이 별도로 필요합니다. 이 글에서는 pod 내부에서 checkpoint를 저장하고 복구하는 방법, 그리고 그 효과에 대해 다룹니다.
S3를 활용한 Checkpoint 저장
Checkpoint 데이터를 저장하는 방법은 여러 가지가 있지만, 클라우드 환경에서는 Amazon S3와 같은 오브젝트 스토리지를 활용하는 것이 가장 간편하고 확장성도 뛰어납니다.
- 작업이 일정 단계(예: epoch, generation 등)에 도달할 때마다 중간 결과를 S3에 저장합니다.
- pod가 재시작되면, S3에서 가장 최근의 checkpoint를 불러와 이어서 작업을 진행합니다.
이 방식은 다음과 같은 장점이 있습니다.
- pod가 어떤 노드에서 실행되든, S3를 통해 항상 동일한 checkpoint에 접근 가능
- 여러 번의 재시작, retry(재시도) 상황에도 불구하고 동일한 결과를 보장
- 작업의 신뢰성과 효율성 향상
GA(Genetic Algorithm)에서의 Checkpoint 활용
특히 유전 알고리즘(Genetic Algorithm, GA)과 같이 여러 세대(generation)에 걸쳐 반복적으로 계산이 이루어지는 작업에서는, 각 세대가 끝날 때마다 checkpoint를 저장하는 것이 매우 효과적입니다.
retry가 필요한 상황(예: pod가 죽거나, 네트워크 장애 등)에서도, checkpoint가 있다면 마지막 저장된 세대부터 바로 이어서 실험을 재개할 수 있습니다. 이는 실험의 시간과 리소스 낭비를 크게 줄여줍니다.
GA에서 반드시 checkpoint에 포함해야 할 정보
- 현재 세대 번호 (
generation) - population (다음 세대에 전달할 parameter set들의 list 혹은 array)
- best solution (지금까지 발견된 최적의 parameter set)
- best fitness (best solution의 fitness 값)
- (선택) random seed, 환경 정보 등 실험 재현성에 필요한 값
이 정보들이 모두 저장되어야, pod가 중간에 죽더라도 정확히 같은 상태에서 실험을 이어갈 수 있습니다.
예시 코드 (Python)
아래는 GA에서 S3를 활용해 checkpoint를 저장/불러오는 예시 코드입니다. 필수 정보가 모두 포함되어 있습니다.
import boto3
import pickle
s3 = boto3.client('s3')
bucket = 'your-s3-bucket'
checkpoint_key = 'checkpoints/ga_generation.pkl'
def save_checkpoint(data, key=checkpoint_key):
s3.put_object(Bucket=bucket, Key=key, Body=pickle.dumps(data))
def load_checkpoint(key=checkpoint_key):
try:
obj = s3.get_object(Bucket=bucket, Key=key)
return pickle.loads(obj['Body'].read())
except s3.exceptions.NoSuchKey:
return None
# 사용 예시
generation_to_run = 0 # 이번에 실행할 generation 번호
population = None
best_solution = None
best_fitness = None
random_seed = 42 # 예시: 실험 재현성을 위해 seed도 저장
# checkpoint 불러오기
checkpoint = load_checkpoint()
if checkpoint:
# 마지막으로 성공한 generation 다음 번호부터 시작
generation_to_run = checkpoint['generation'] + 1
population = checkpoint['population']
best_solution = checkpoint['best_solution']
best_fitness = checkpoint['best_fitness']
random_seed = checkpoint.get('random_seed', 42)
while generation_to_run < MAX_GENERATION:
# ... GA 연산 (현재 generation_to_run에 대한) ...
# population, best_solution, best_fitness 업데이트
# 현재 generation 작업이 성공적으로 끝났으므로 checkpoint 저장
save_checkpoint({
'generation': generation_to_run, # 성공적으로 완료된 generation 번호
'population': population, # 다음 세대에 전달할 parameter set
'best_solution': best_solution,
'best_fitness': best_fitness,
'random_seed': random_seed
})
generation_to_run += 1
참고: 실험의 완전한 재현성을 위해서는 random seed, 환경 정보도 함께 저장하는 것이 좋습니다. (동일한 docker image 내에서 실행되는 경우에는 대부분 필요하지 않습니다.) 필요에 따라 checkpoint에 추가하세요.
Checkpoint 적용 전후의 시간 및 성공률 비교
실제 예시로, 한 generation에 약 10초가 걸리는 GA 작업을 50 generation 동안 수행한다고 가정해보겠습니다. 중간에 pod가 실패하여 작업이 중단되는 상황을 비교해보면 다음과 같습니다.
시간 비교
case 1 - no checkpoint
- 1 ~ 30 (30 generation 동안 정상 진행, 이후 실패)
- 1 ~ 25 (25 generation 동안 정상 진행, 이후 실패)
- 1 ~ 50 (50 generation 동안 정상 진행, 최종 성공)
총 수행한 generation 수: 30 + 25 + 50 = 105회
- 총 소요 시간: 105 × 10초 = 1,050초 (약 17.5분)
case 2 - checkpoint
- 1 ~ 30 (30 generation 동안 정상 진행, 이후 실패)
- 30 ~ 50 (21 generation 동안 정상 진행, 최종 성공)
총 수행한 generation 수: 30 + 21 = 51회
- 총 소요 시간: 51 × 10초 = 510초 (약 8.5분)
비교 및 효과
- checkpoint 없이 재시작: 1,050초
- checkpoint로 이어서 재시작: 510초
- 절반 이상의 시간과 리소스를 절약할 수 있습니다.
최종 성공 가능성 향상
checkpoint를 활용하면, pod가 여러 번 실패하더라도 항상 마지막 저장 지점부터 이어서 작업을 재개할 수 있습니다. 이는 단순히 시간을 아끼는 것뿐만 아니라, 실험의 최종 성공 가능성도 크게 높여줍니다. 반복적인 실패에도 불구하고, 전체 실험을 완주할 수 있는 확률이 높아집니다.
예를 들어, 각 generation이 98% 확률로 성공한다고 가정하고, 총 50개의 generation을 최대 3번의 pod retry 안에 모두 성공시켜야 하는 상황을 비교해보겠습니다.
case 1 - no checkpoint
# 각 try 의 실패 확률 = 1 - 0.98 ** 50
>>> 1 - 0.98 ** 50
0.6358303199128832
# 세번 모두 실패할 확률
>>> 0.6358303199128832 ** 3
0.2543740234375
# 세번 중 최소 한번 성공할 확률
>>> 1 - 0.2543740234375
0.7456259765625
즉, 약 75% 확률로 최종 성공할 수 있습니다.
case 2 - checkpoint
# 개별 generation 하나가 세 번 모두 실패할 확률
>>> 0.02 ** 3
8e-06
# 이 값은 "하나의 generation이 pod 1, 2, 3 모두에서 실패할 확률"을 의미합니다.
# 실제로 generation 단위로 retry가 되는 것은 아니지만,
# pod-level retry + checkpoint resume 구조에서 어떤 generation은 최대 3번까지 시도될 수 있습니다.
# 50개의 generation이 모두 3번 이내에 성공할 확률
>>> (1 - 8e-06) ** 50
0.9996000399986667
즉, 약 99.96% 확률로 최종 성공할 수 있습니다.
요약: checkpoint는 retry 상황에서 시간과 리소스를 절약할 뿐만 아니라, 실험의 성공률까지 높여주는 중요한 전략입니다.
결론
Kubernetes 환경에서 S3를 활용한 checkpointing은, 특히 반복적이고 시간이 오래 걸리는 작업(예: GA)에서 pod 재시작이나 retry(재시도) 상황에 따른 리소스 낭비를 크게 줄여줍니다. 각 세대(generation)마다 checkpoint를 저장하면, 언제든지 중단된 지점부터 효율적으로 작업을 이어갈 수 있습니다. GA의 경우 population, best solution, best fitness, random seed 등 필수 정보를 모두 저장해야 완전한 복원이 가능합니다.