Improving AVM with Duplicate Data Integration
Topic
다세대 주택과 오피스텔에 대한 거래 데이터를 모두 사용할 때 오피스텔 데이터가 다세대 주택 데이터의 약 1/10 수준으로 클래스 불균형이 존재합니다. 전처리 없이 결합된 데이터를 사용할 때, 우리는 모델이 훈련 중에 오피스텔에 비해 다세대 주택 데이터에 상대적으로 더 적합함을 발견했고, 그 결과 오피스텔의 예측 가격이 더 높았습니다. 따라서 우리는 다세대 주택과 오피스텔에 대한 통합 모델을 개발할 때 데이터 불균형으로 인한 편향을 줄이는 방법을 실험하는 것을 목표로 합니다.
Method
데이터 불균형 문제를 해결하기 위해 고려할 수 있는 첫 번째 접근 방식은 손실 함수를 사용자 정의하는 것입니다. 그러나 현재 사용 중인 AutoGluon 패키지에서는 손실 함수를 임의로 수정하기 어려웠고, 사용자 정의는 주관적인 방법으로서 한계가 있었습니다. 따라서 우리는 “데이터 중복을 손실 대신 사용하여 특정 데이터 포인트의 손실이 전체 손실 함수에 미치는 영향을 더 크게 만들 수 있다”는 가설을 테스트했습니다. 이 아이디어는 AutoGluon 패키지와 독립적이면서도 더 체계적이라는 기준을 충족합니다.
Result & Analysis
Changes by Area and Type
지역 및 유형별 변화를 플로팅할 때, 중복 데이터를 사용한 통합 모델은 일반적으로 기존 통합 모델에 비해 낮은 결과를 보여준다는 것을 확인할 수 있습니다. 하지만,
- 오피스텔의 경우 두 모델 간에 선형적 관계가 나타나는 반면, 공동주택의 경우 특별한 선형적 관계가 나타나지 않았으며, 두 모델 간의 차이가 비교적 큰 경우도 있습니다.
- 오피스텔의 경우 규모가 커질수록 두 모델 간 차이가 극단적으로 나타나는 사례(수직·수평 범위가 넓어지고 추세에서 벗어나는 지점이 많아짐)가 많았습니다.
- Figure
- 왼쪽: 다세대 주택 / 오른쪽: 오피스텔
- X축 : 기존 통합 모델 / Y축 : 중복 데이터를 활용한 통합 모델
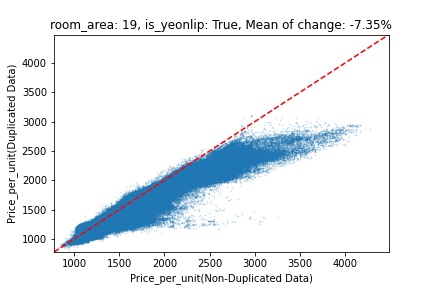
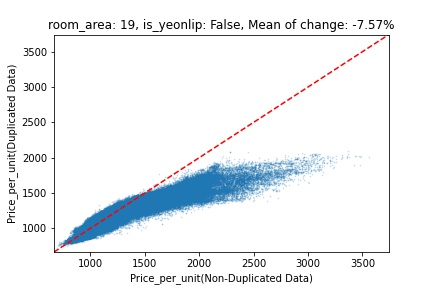
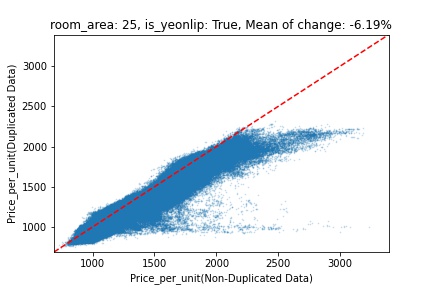
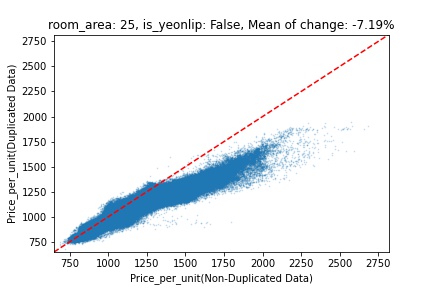
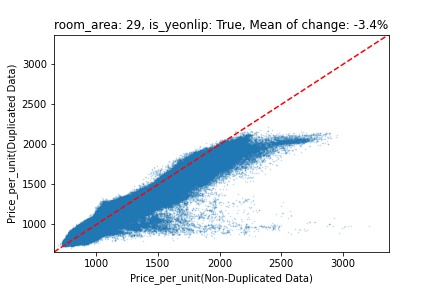
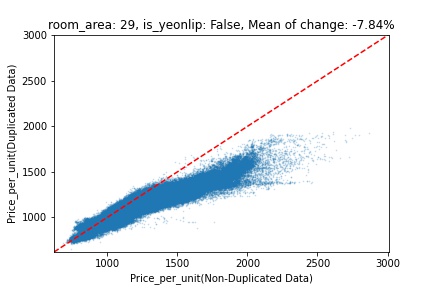
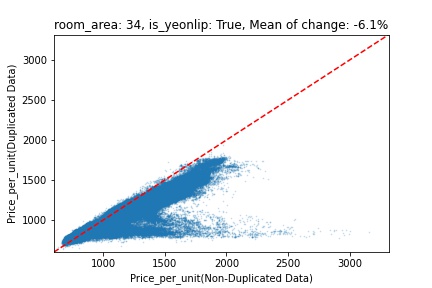
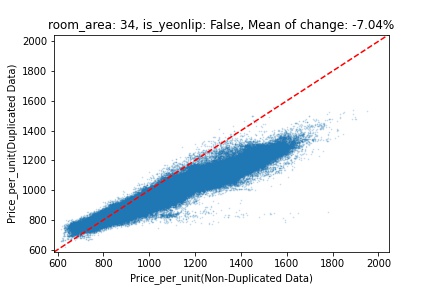
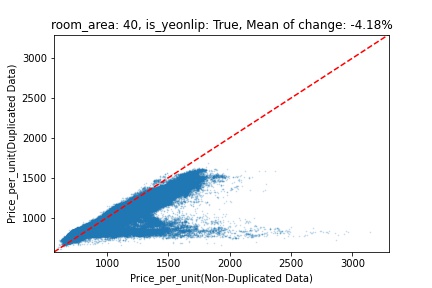
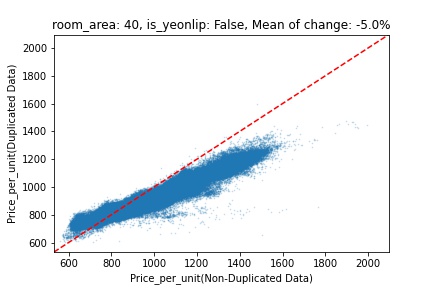
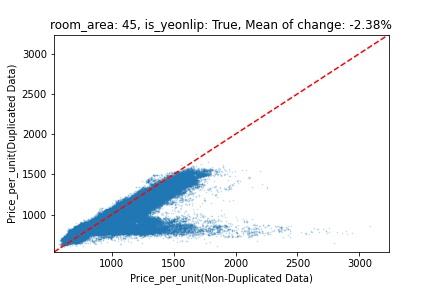
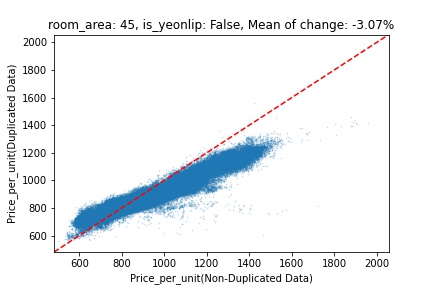
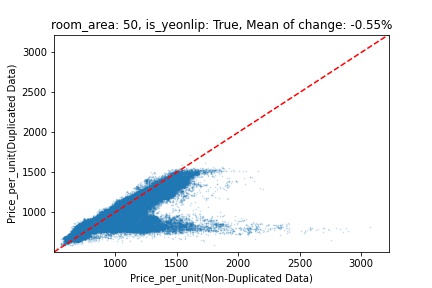
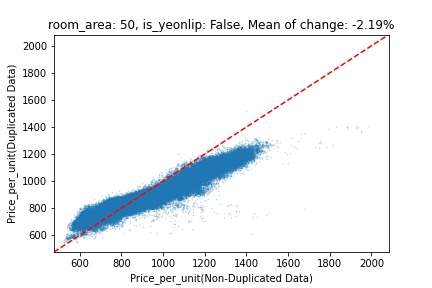
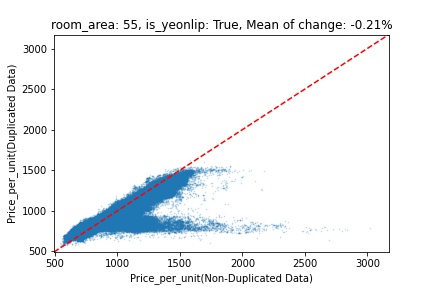
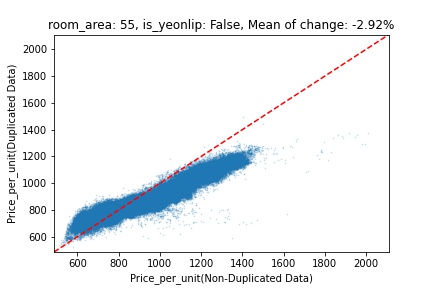
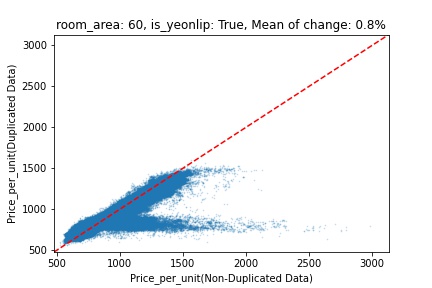
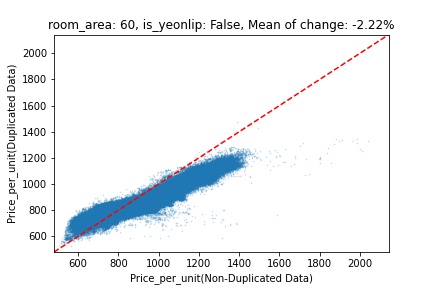
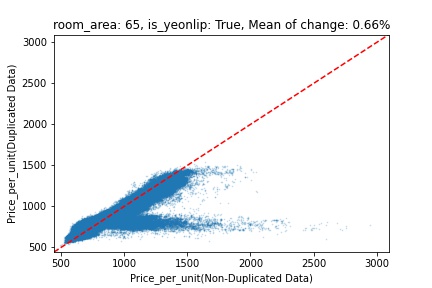
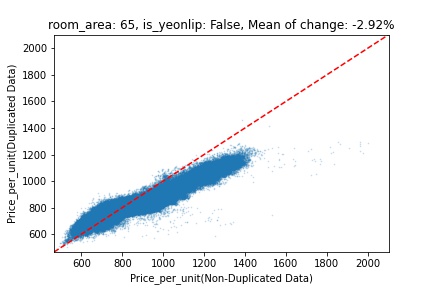
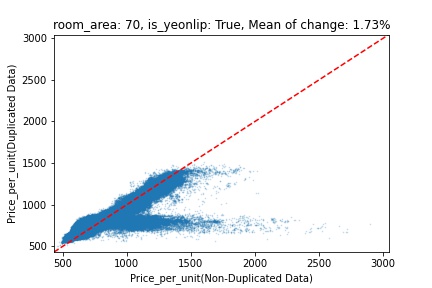
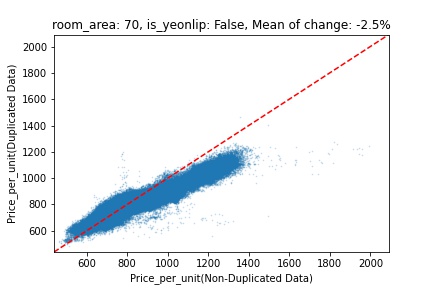
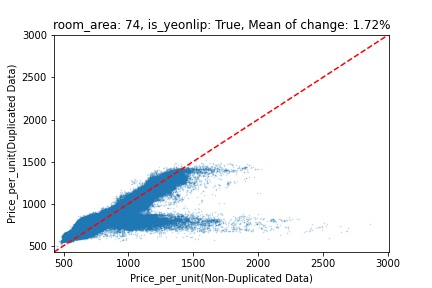
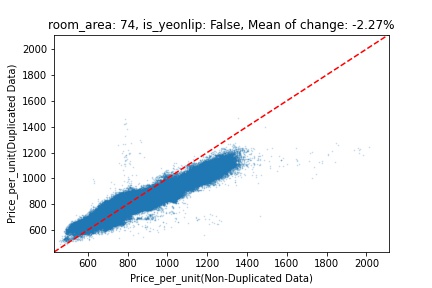
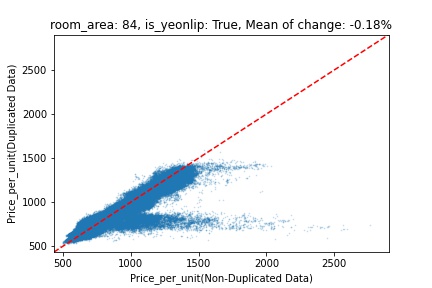
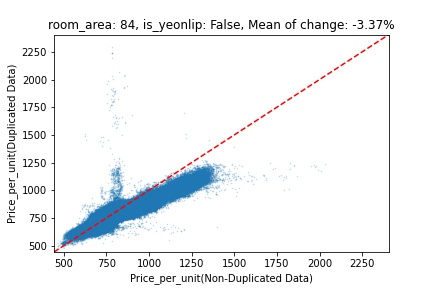
Change Amount Scatter Plot
지역별로 변화량에 차이가 있는지 확인하기 위해 지도에 변화를 매핑했습니다. 다세대 주택의 경우 강서구 지역에서 두 모델 간에 큰 차이가 있는 사례가 많고, 오피스텔의 경우 서대문구 지역에서 많은 차이가 관찰되었습니다. 추가 실험과 투자팀 QA를 통해 유의미한 차이가 있는 지역 간에 어떤 공통점이 있는지 파악하는 것이 필요합니다.
- Figure
- 왼쪽: 다세대 주택 / 오른쪽: 오피스텔
- 색상 : 변화량
.png)
.png)
.png)
.png)
.png)
.png)