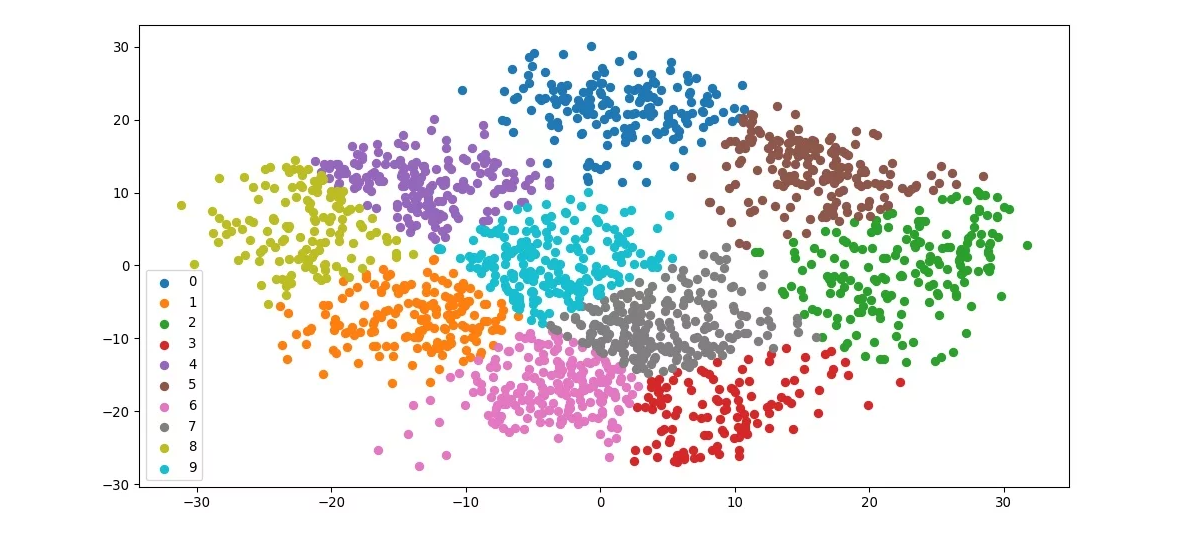
The K-Means clustering algorithm is the algorithm that clusters to a K number when given data. And it operates as a way to minimize between each cluster about distance difference. This algorithm is a type of the Unsupervised-Learning and serves to label unlabeled input data.
The K-Means algorithm belongs to a partitioning method among clustring method. A partitioning method is a way of splitting that divides multiple partitions when given data. For example, let's assume that n data objects are input. That's when partitioning method divides the given data into K groups less than N, at this time, each group forms a cluster. That is, dividing a piece of data into one or more data objects. K-means clustering, divided by 10
Implementation
The operation flow of the K-Means clustering consists of 5 steps following:
Select up a K (the count of clusters) and enter data
Set initial centroids of clusters randomly
Assign the data to each cluster based on the nearest centroid
Recalculate the new centroids of clusters and re-execute step-4
Terminate if no longer locations of centroids aren't updated
Let's implement the K-Means algorithm based on the steps above. First, we define the KMeans object. As input, it receives the number of clusters(K) to divide, points cloud, and iteration_count which is the number of centroid update iterations
class KMeans(PointHelper):
def __init__(self, points=None, k=3, iteration_count=20, random_seed=0):
"""KMeansCluster simple implementation using Rhino Geometry
Args:
points (Rhino.Geometry.Point3d, optional): Points to classify. Defaults to None. if points is None, make random points
k (int, optional): Number to classify. Defaults to 3.
iteration_count (int, optional): Clusters candidates creation count. Defaults to 20.
random_seed (int, optional): Random seed number to fix. Defaults to 0.
"""
PointHelper.__init__(self)
self.points = points
self.k = k
self.iteration_count = iteration_count
self.threshold = 0.1
import random # pylint: disable=import-outside-toplevel
self.random = random
self.random.seed(random_seed)
Next, Initialize the centroids of clusters as much as the number of K by selecting the given points cloud as much as K randomly. If the initial centroid setting is done, calculate the distance between each centroid and the given points cloud, and assign the data at the cluster which is the closest distance. Now we should update all the centroids of clusters. We need to compute centroids of initial clusters(points cloud clusters) for that.
Finally, compute the distance between the updated centroid and the previous centroid. If this distance does not no longer changes, terminate. Otherwise, just iterate on key things which are explained above.
def kmeans(self, points, k, threshold):
"""Clusters by each iteration
Args:
points (Rhino.Geometry.Point3d): Initialized given points
k (int): Initialized given k
threshold (float): Initialized threshold
Returns:
Tuple[List[List[Rhino.Geometry.Point3d]], List[List[int]]]: Clusters by each iteration, Indices by each iteration
"""
centroids = self.random.sample(points, k)
while True:
clusters = [[] for _ in centroids]
indices = [[] for _ in centroids]
for pi, point in enumerate(points):
point_to_centroid_distance = [
point.DistanceTo(centroid) for centroid in centroids
]
nearest_centroid_index = point_to_centroid_distance.index(
min(point_to_centroid_distance)
)
clusters[nearest_centroid_index].append(point)
indices[nearest_centroid_index].append(pi)
shift_distance = 0.0
for ci, current_centroid in enumerate(centroids):
if len(clusters[ci]) == 0:
continue
updated_centroid = self.get_centroid(clusters[ci])
shift_distance = max(
updated_centroid.DistanceTo(current_centroid),
shift_distance,
)
centroids[ci] = updated_centroid
if shift_distance < threshold:
break
return clusters, indices
Now we can get the point clusters by setting the K, from the code above. And you can see the detailed code for the K-Means at this link. Implemented K-means clustering, divided by 10 From the left, Given Points · Result clusters
K-Rooms clusters
The K-Means algorithm is used to cluster as much as the number of K, given points, like described above. If you utilize it, you can divide a given architectural boundary as much as the number of K. It means that K number of rooms can be obtained.
Before writing the code, set the following order.
As input, it receives the building exterior wall line (closed line) and how many rooms to divide into
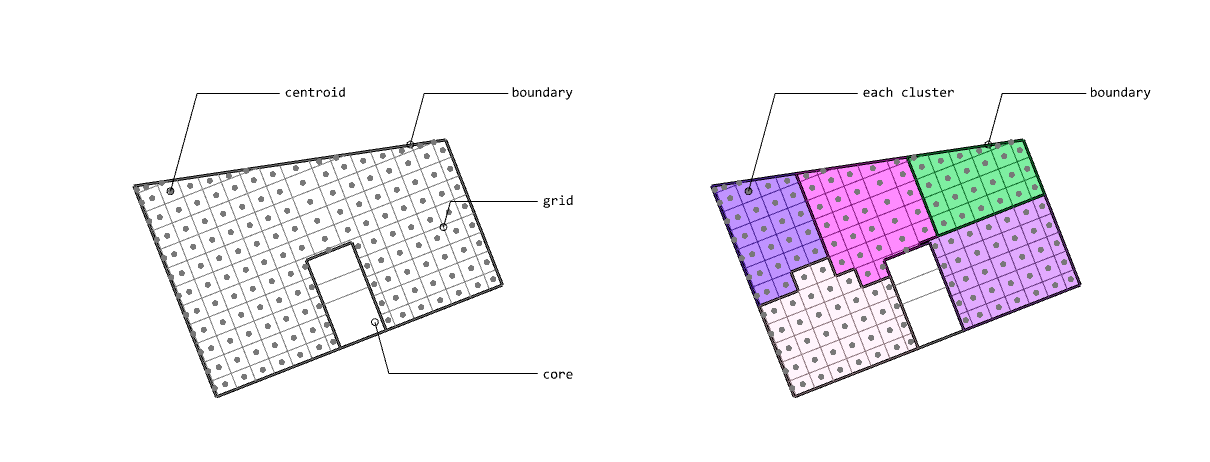
Create an oriented bounding box and create a grid
Insert the grid center points into the K-Means clustering algorithm, implemented above
Grids are merged based on the indices of the clustered grid center points
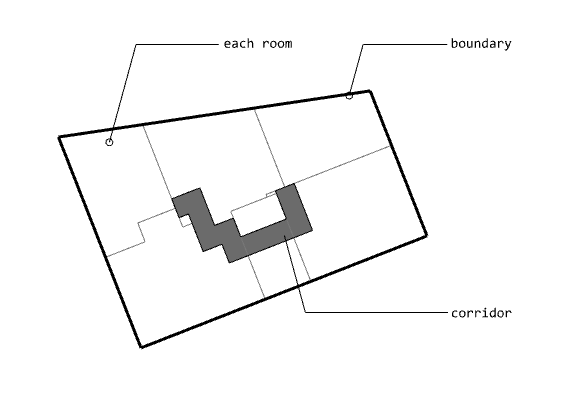
Search for the shortest path from the core to each room and create a corridor
Now let's implement the K-Rooms cluster algorithm. Define the KRoomsClusters class as follows and take as input what you defined in step 1. And inherit the KMeans class.
class KRoomsCluster(KMeans, PointHelper, LineHelper, ConstsCollection):
"""
To use the inherited moduels, refer the link below.
https://github.com/PARKCHEOLHEE-lab/GhPythonUtils
"""
def __init__(self, floor, core, hall, target_area, axis=None):
self.floor = floor
self.core = core
self.hall = hall
self.sorted_hall_segments = self.get_sorted_segment(self.hall)
self.target_area = target_area
self.axis = axis
KMeans.__init__(self)
PointHelper.__init__(self)
LineHelper.__init__(self)
ConstsCollection.__init__(self)
Next, we create an OBB(oriented bounding box) to create the grid. OBB is for defining the grid xy axes. (See this link to see the OBB creation algorithm) Then, create grid and grid centroid, extract the clustering indices by putting the center points of the grid and the K value, and then merge all the grids that exist in the same cluster. K-Rooms clustering key process, divided by 5 From the left, Grid and centroids creation · Divided rooms
def _gen_grid(self):
self.base_rectangles = [
self.get_2d_offset_polygon(seg, self.grid_size)
for seg in self.sorted_hall_segments[:2]
]
counts = []
planes = []
for ri, base_rectangle in enumerate(self.base_rectangles):
x_vector = (
rg.AreaMassProperties.Compute(base_rectangle).Centroid
- rg.AreaMassProperties.Compute(self.hall).Centroid
)
y_vector = copy.copy(x_vector)
y_transform = rg.Transform.Rotation(
math.pi * 0.5,
rg.AreaMassProperties.Compute(base_rectangle).Centroid,
)
y_vector.Transform(y_transform)
base_rectangle.Translate(
(
self.sorted_hall_segments[0].PointAtStart
- self.sorted_hall_segments[0].PointAtEnd
)
/ 2
)
base_rectangle.Translate(
self.get_normalized_vector(x_vector) * -self.grid_size / 2
)
anchor = rg.AreaMassProperties.Compute(base_rectangle).Centroid
plane = rg.Plane(
origin=anchor,
xDirection=x_vector,
yDirection=y_vector,
)
x_proj = self.get_projected_point_on_curve(
anchor, plane.XAxis, self.obb
)
x_count = (
int(math.ceil(x_proj.DistanceTo(anchor) / self.grid_size)) + 1
)
y_projs = [
self.get_projected_point_on_curve(
anchor, plane.YAxis, self.obb
),
self.get_projected_point_on_curve(
anchor, -plane.YAxis, self.obb
),
]
y_count = [
int(math.ceil(y_proj.DistanceTo(anchor) / self.grid_size)) + 1
for y_proj in y_projs
]
planes.append(plane)
counts.append([x_count] + y_count)
x_grid = []
for base_rectangle, count, plane in zip(
self.base_rectangles, counts, planes
):
xc, _, _ = count
for x in range(xc):
copied_rectangle = copy.copy(base_rectangle)
vector = plane.XAxis * self.grid_size * x
copied_rectangle.Translate(vector)
x_grid.append(copied_rectangle)
y_vectors = [planes[0].YAxis, -planes[0].YAxis]
y_counts = counts[0][1:]
all_grid = [] + x_grid
for rectangle in x_grid:
for y_count, y_vector in zip(y_counts, y_vectors):
for yc in range(1, y_count):
copied_rectangle = copy.copy(rectangle)
vector = y_vector * self.grid_size * yc
copied_rectangle.Translate(vector)
all_grid.append(copied_rectangle)
union_all_grid = rg.Curve.CreateBooleanUnion(all_grid, self.TOLERANCE)
for y_count, y_vector in zip(y_counts, y_vectors):
for yc in range(1, y_count):
copied_hall = copy.copy(self.hall)
copied_hall.Translate(
(
self.sorted_hall_segments[0].PointAtStart
- self.sorted_hall_segments[0].PointAtEnd
)
/ 2
)
vector = y_vector * self.grid_size * yc
copied_hall.Translate(vector)
all_grid.extend(
rg.Curve.CreateBooleanDifference(
copied_hall, union_all_grid
)
)
self.grid = []
for grid in all_grid:
for boundary in self.boundaries:
tidied_grid = list(
rg.Curve.CreateBooleanIntersection(
boundary.boundary, grid, self.TOLERANCE
)
)
self.grid.extend(tidied_grid)
self.grid_centroids = [
rg.AreaMassProperties.Compute(g).Centroid for g in self.grid
]
Finally, connect each room with a hallway and you're done! (I implemented Dijkstra algorithm for the shortest-path algorithm. You can check the implementation through the following link. I will do a post on this at the next opportunity.) Corridor creation
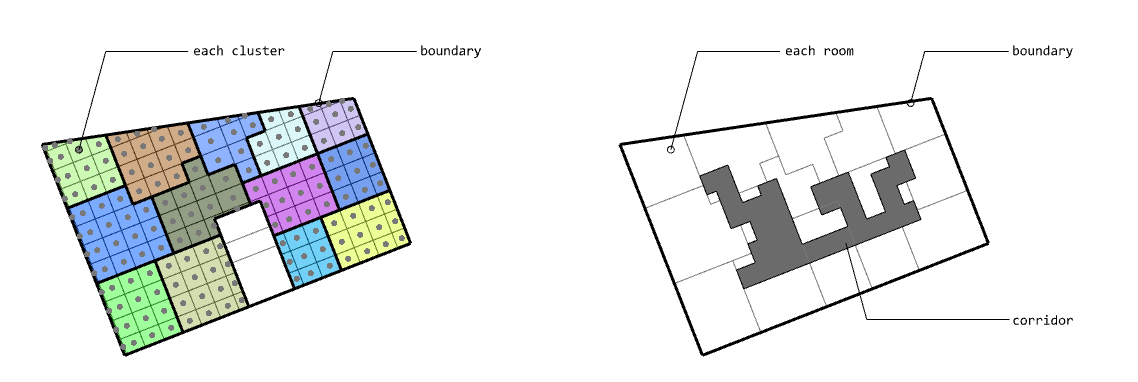
Limitation of K-Rooms clusters
The K-Rooms Clusters algorithm we implemented is still incomplete. The images shown above are valid results when the K value is small. When the K value increases and the number of rooms increases, a problem in which an architecturally appropriate shape cannot be derived. For example below: Improper shapes, divided by 13 From the left, K-Rooms · Result corridor All we need to do further to solve this problem is to define the appropriate shape and create the logic to mitigate it with post-processing. And you can see the whole code of K-Rooms clusters at this link.