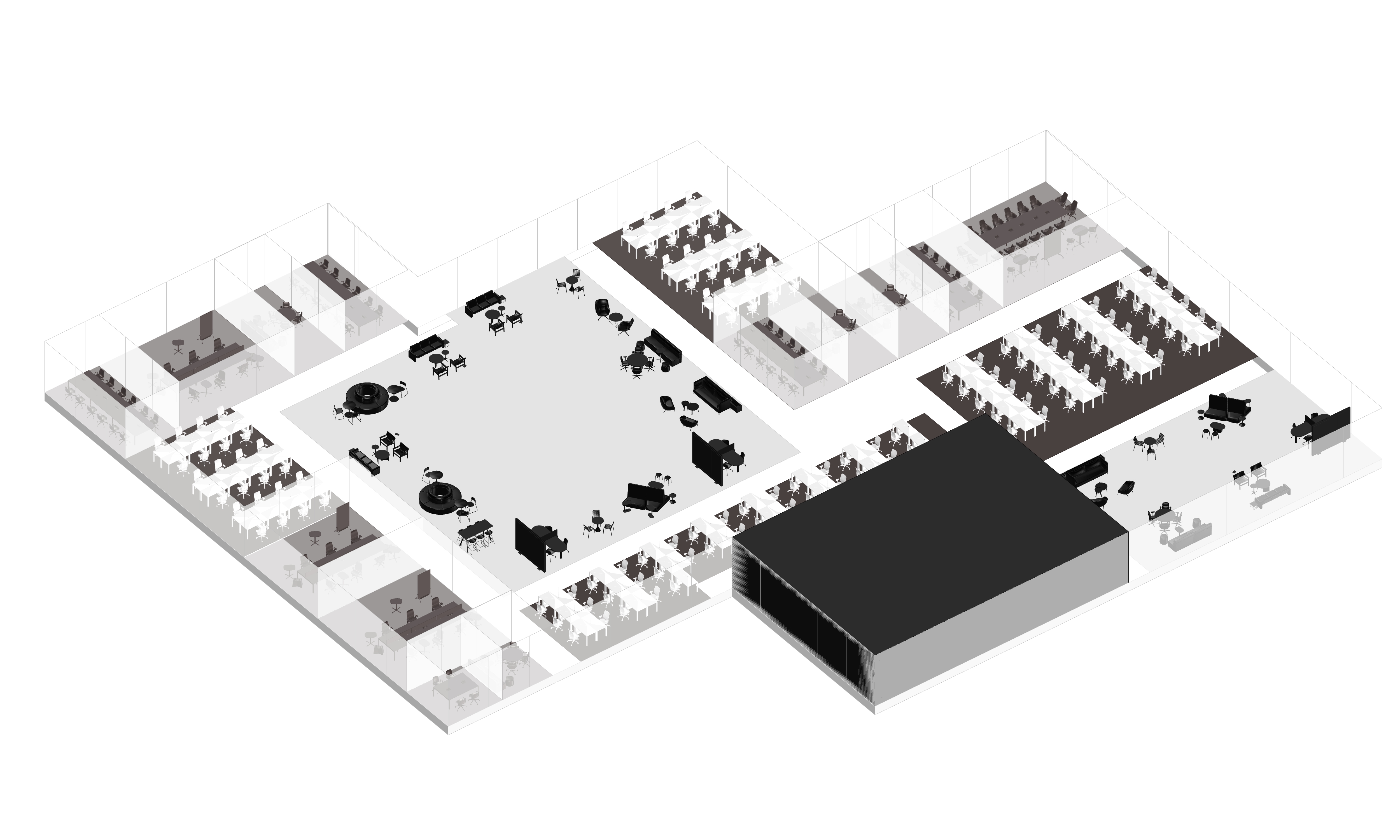
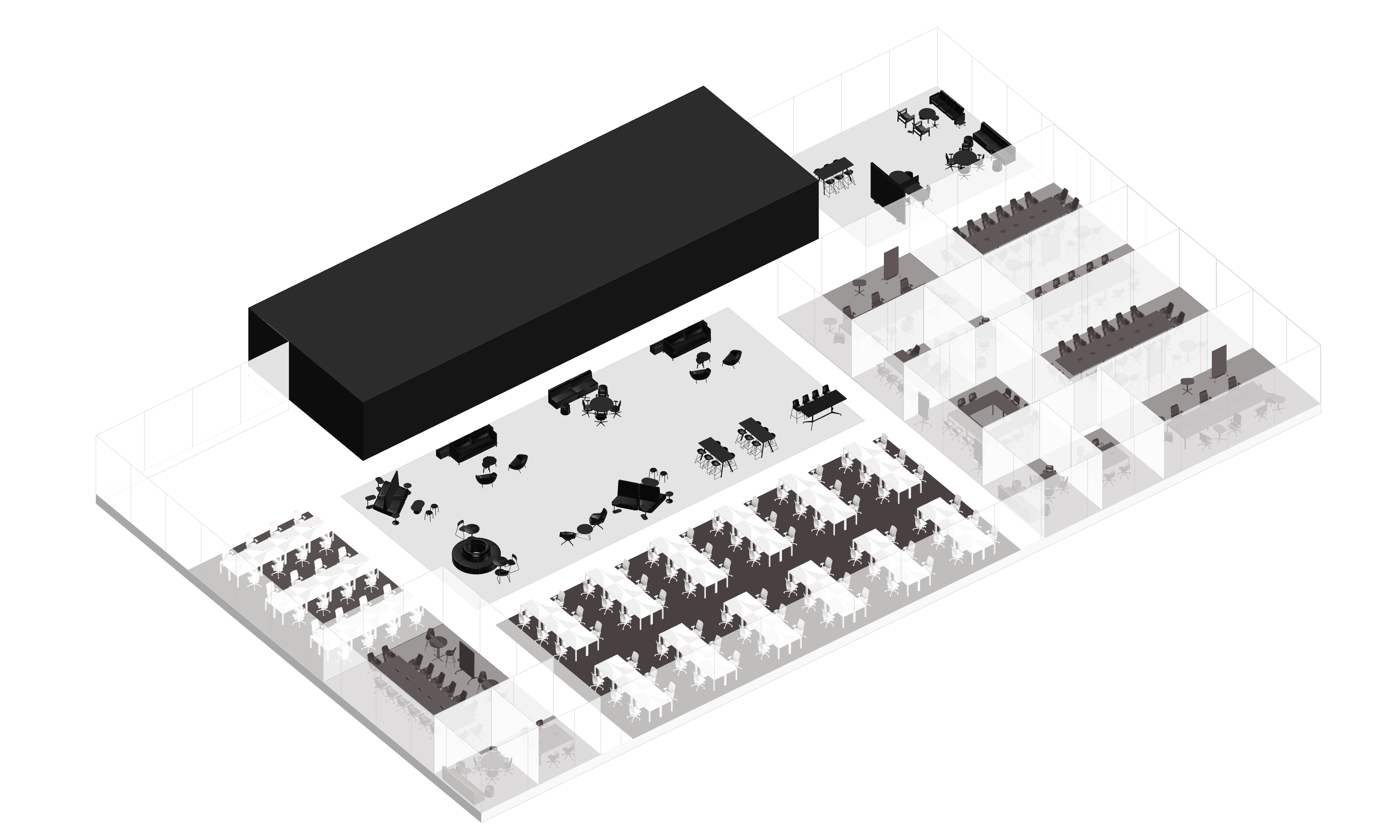
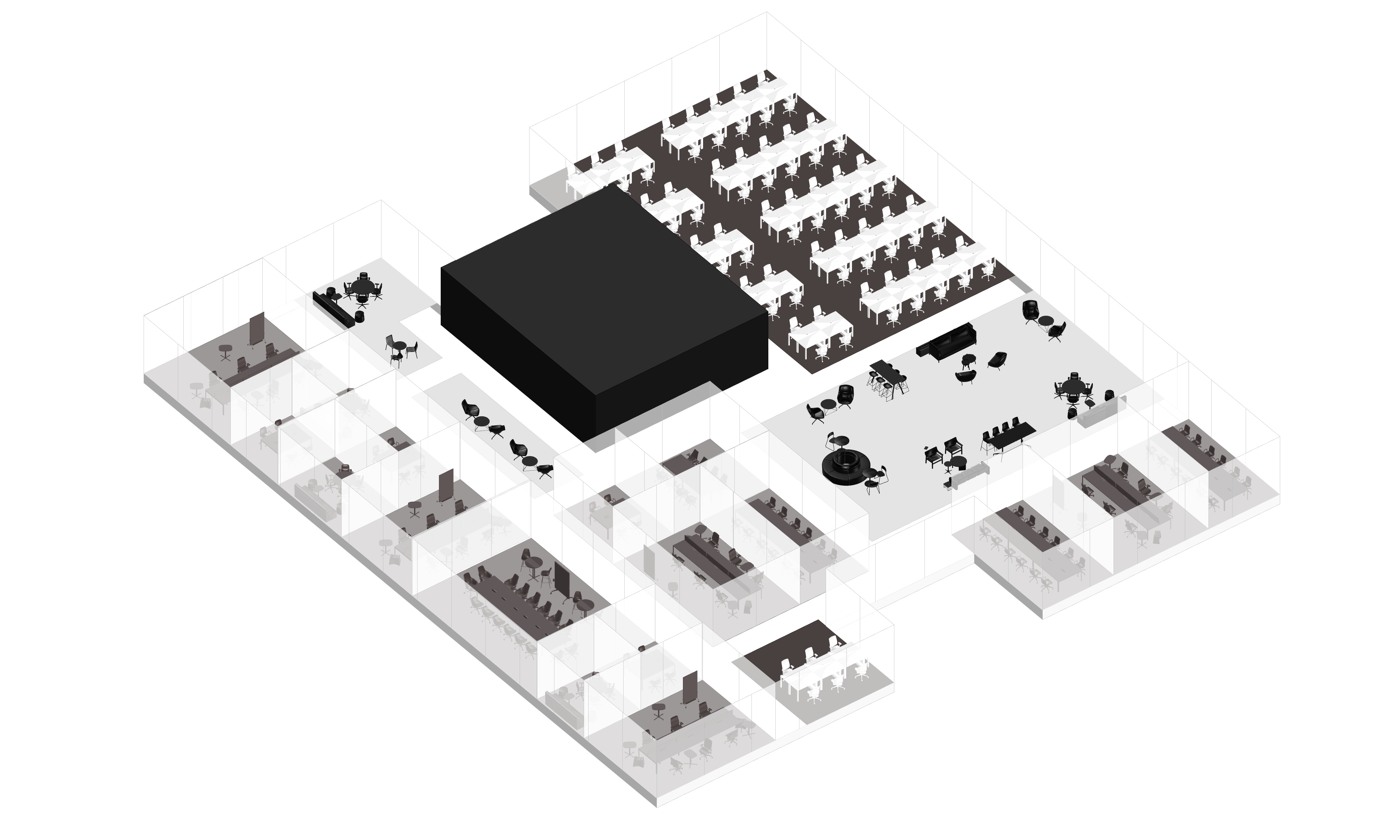
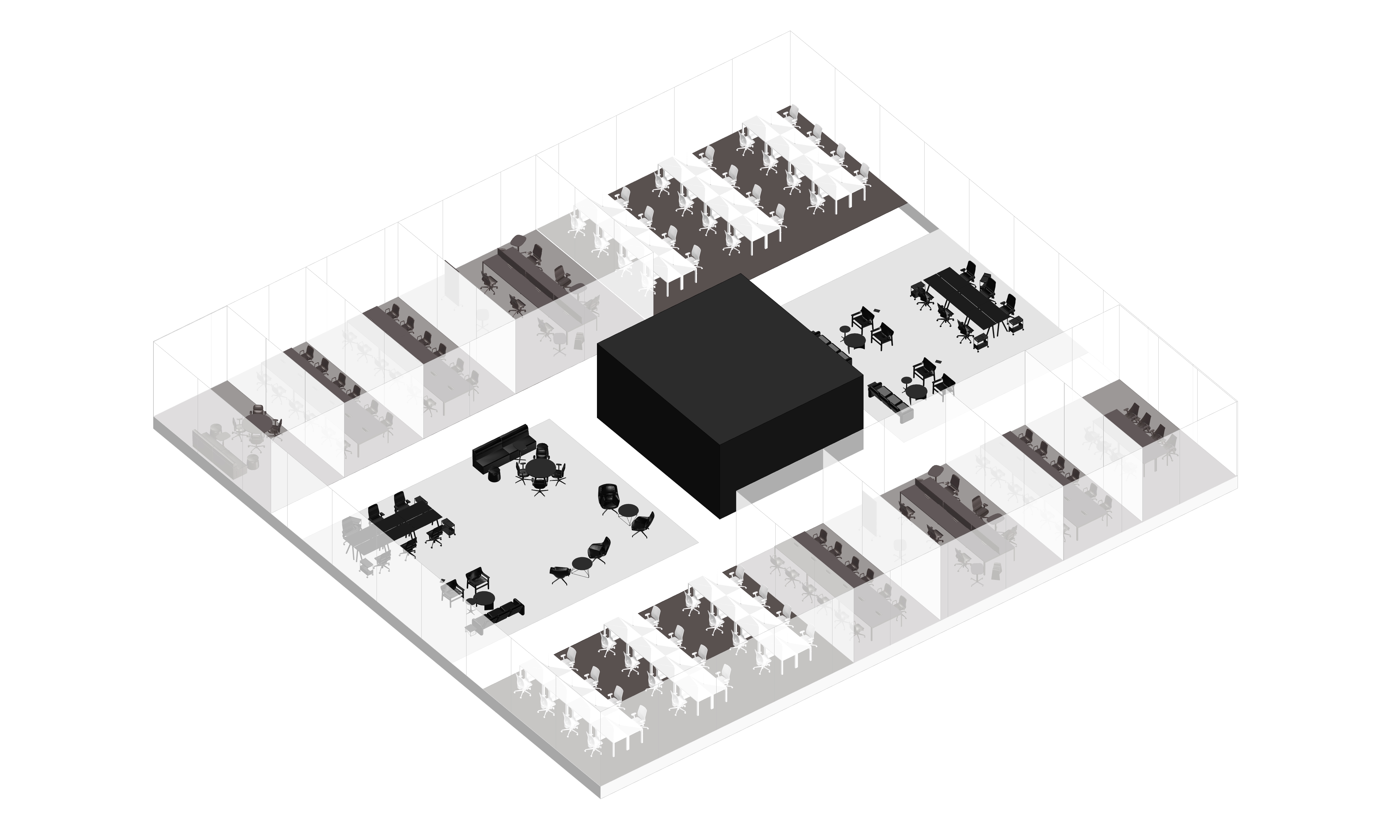
LLM-based office layout generation
Introduction
사무실 레이아웃을 계획하는 과정은 생각보다 복잡하다. 부서를 어떻게 배치할지, 부서 간 동선은 어떻게 연결할지, 창문은 누구에게 우선 배정할지 등 다양한 의사결정이 필요하기 때문이다. 예전에는 이런 문제들을 인간 디자이너의 경험과 직관에만 의존해 해결해왔지만, 이제는 대형 언어 모델(LLM)과 파라메트릭 모델, 그리고 최적화 알고리즘을 결합해 훨씬 효율적이면서 창의적인 결과를 얻을 수 있게 되었다.
이 글에서는 인간이 전통적으로 어떻게 레이아웃을 설계하는지와 LLM이 그 과정을 어떻게 보완하는지, 그리고 파라메트릭 모델과 최적화 알고리즘이 어떻게 함께 작동해 최고의 결과를 만들어내는지 살펴보겠다. 또한 실제로 어떻게 영역을 나누고, 창문 비율을 조정하며, 영역 간 인접 관계를 최적화하는지도 구체적으로 설명한다.
Traditional Design Methods
인간 디자이너는 오피스 레이아웃을 짤 때, 일반적으로 다음 단계를 거쳐 왔다.
- 사용자 요구 및 프로그램 파악
- 고객(또는 회사)의 규모, 각 팀 인원 수, 필요한 공간 종류(개방형 업무공간·개인 사무실·회의실·휴게 라운지 등)를 조사한다.
- 조직의 업무 방식, 부서 간 협업 필요성, 공간적 제약(건물 구조나 규정)을 종합적으로 파악한다.
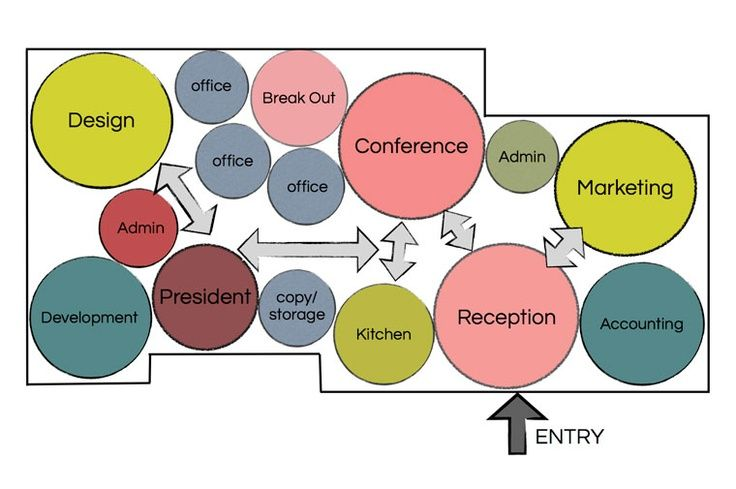
- 인접성 계획(Adjacency Planning)
- 어떤 부서끼리 가까이 있어야 하는지, 누가 자주 소통해야 하는지 등을 확인한다.
- 버블 다이어그램이나 인접 행렬(Adjacency Matrix) 같은 방식으로 “이 부서와 저 부서는 밀접히 협력해야 하므로 가깝게 둬야 한다”는 식의 관계를 시각화한다.
- 공간 배분(Space Planning)
- 실제 건물 평면을 바탕으로, 어느 정도 면적을 각 공간에 할당할지 결정한다.
- 기둥, 벽, 창문, 비상 통로 등 구조적 요인을 고려해 구역을 나눈다. 이때 “물리적인 동선이 편리한지”, “소음은 적절히 분산되는지” 등을 사람의 직관으로 검토한다.
- 시안(스케치)을 여러 번 그려가며 가구, 칸막이, 출입문, 복도 등을 조금씩 옮겨본다. “퍼즐 맞추기”처럼 수많은 시도를 반복한다.
- 실제 레이아웃 확정 및 디테일 조정
- 어느 정도 ‘이상적’으로 보이는 평면안이 나오면, 세부 치수를 정하고 가구 배치나 벽체 마감 등을 구체화한다.
- 현장 상황이나 고객의 피드백을 받아 최종 수정을 진행한다.
이 전통적인 방법은 디자이너가 오랜 경험과 직관을 발휘할 수 있다는 장점이 있지만, 동시에 시간이 많이 들고 여러 반복 시도가 필요하다는 한계가 있다. 또, 건물 규정과 협업 필요성, 브랜드 아이덴티티처럼 다양한 요인을 모두 빠짐없이 고려하기가 쉽지 않다.
LLMs, Parametric Models, and Optimization Algorithms
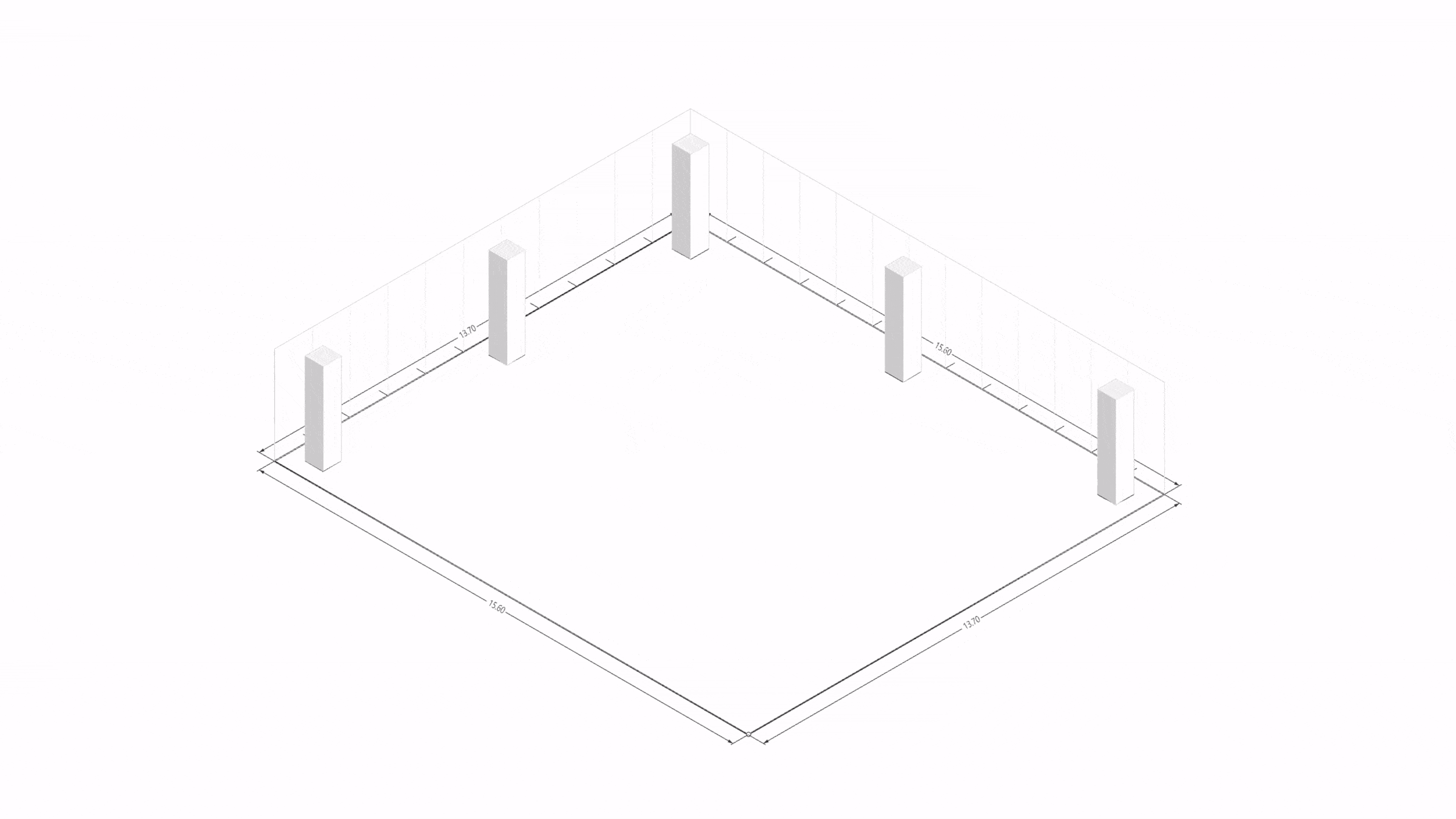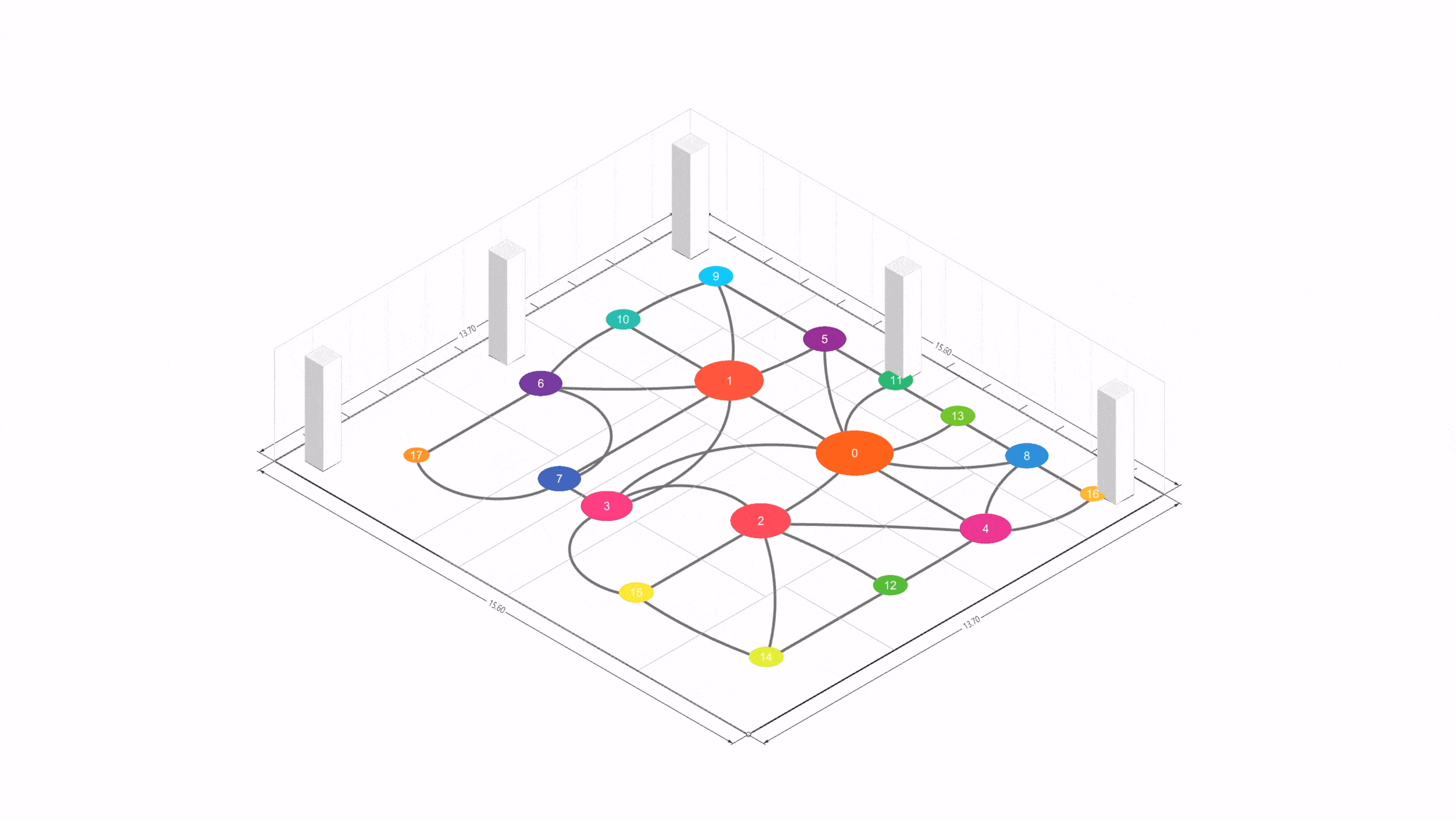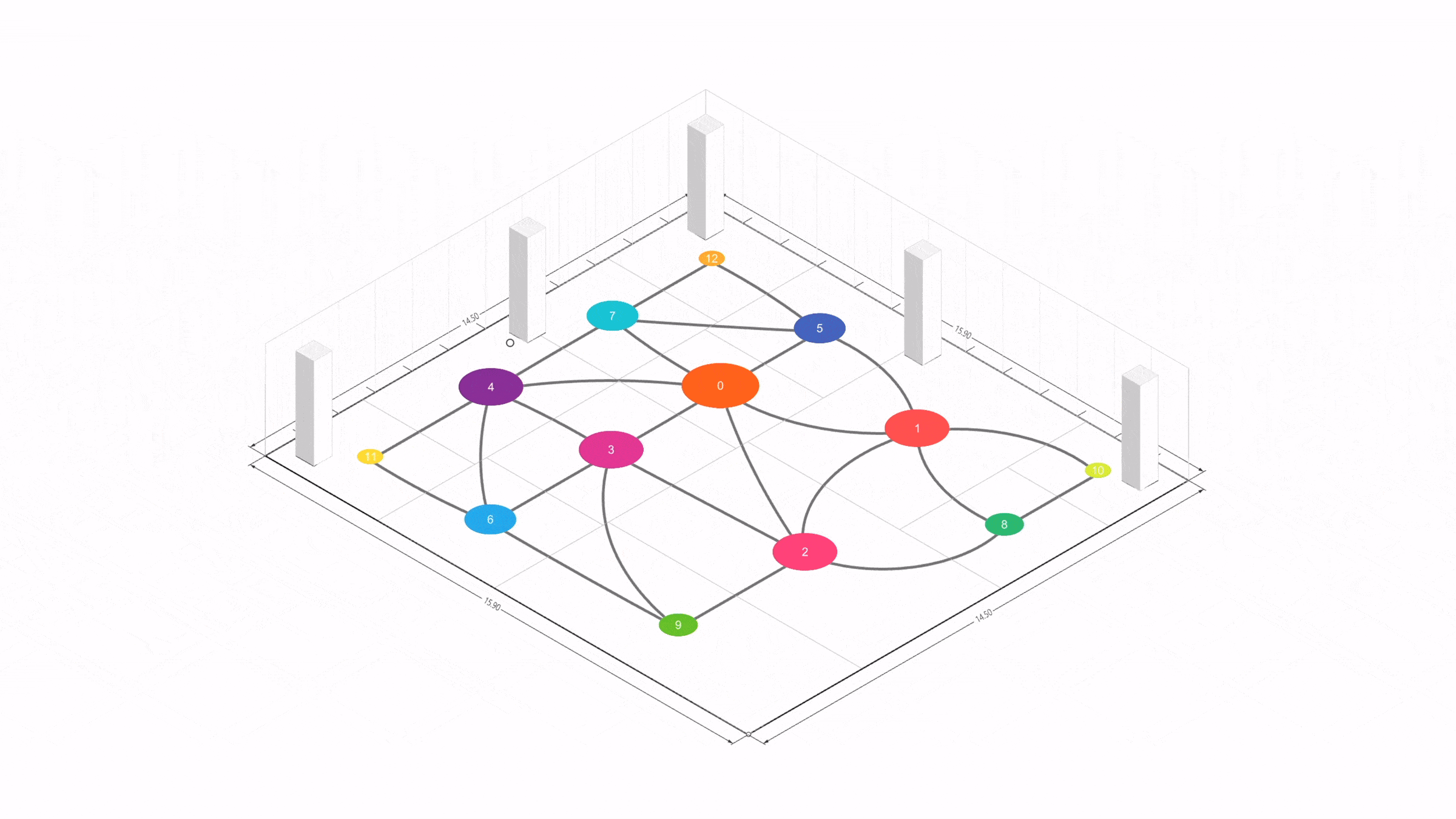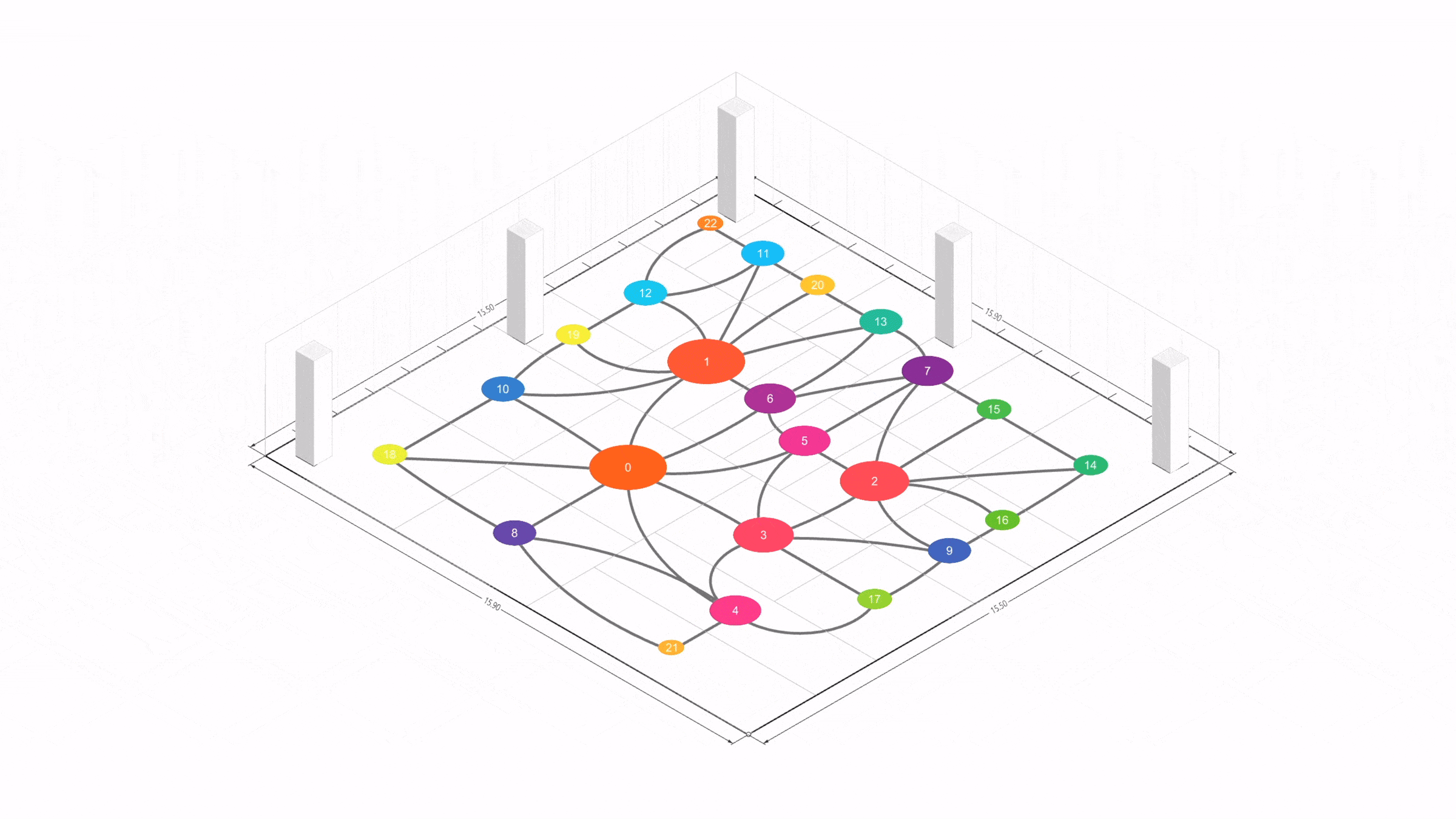
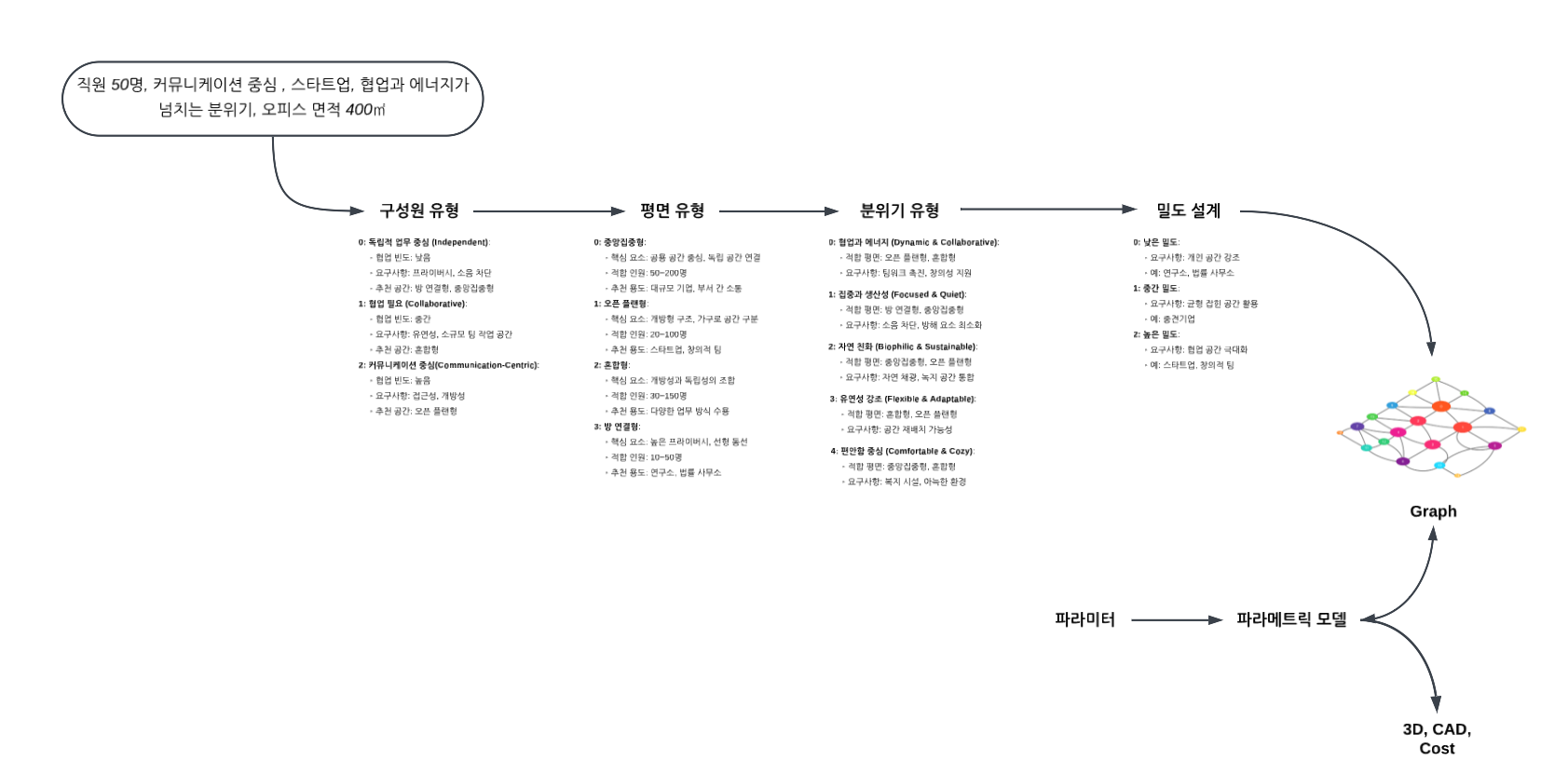
이제 이런 전통적 프로세스에 LLM과 파라메트릭 모델, 최적화 알고리즘을 접목하면 크게 세 가지 축을 살펴볼 수 있다.
- LLM(Large Language Model)
- 사람이 자연어로 작성한 요구사항(예: “사무실이 보수적 분위기라 창가에 사적 업무공간을 배치하고 싶다”)을 이해한다.
- 설계 전략(“협업 공간 비율은 25%만 필요”, “개인 집중 업무실은 창문 옆에 최대한 배치”) 같은 지침을 토대로 영역 개수, 용도 배분, 창문 배정 비율 등 핵심 의사결정을 내려준다.
- 파라메트릭 모델
- 디자이너가 평소 스케치하고 조정하던 과정을 매개변수(파라미터)로 정의한다.
- 영역을 쪼개고 채우는 알고리즘은 규칙기반으로 rectangle decomposition과 bin packing 알고리즘을 사용한다.
- 모델은 이 파라미터들을 변경하며 다양한 배치안을 자동으로 생성한다.
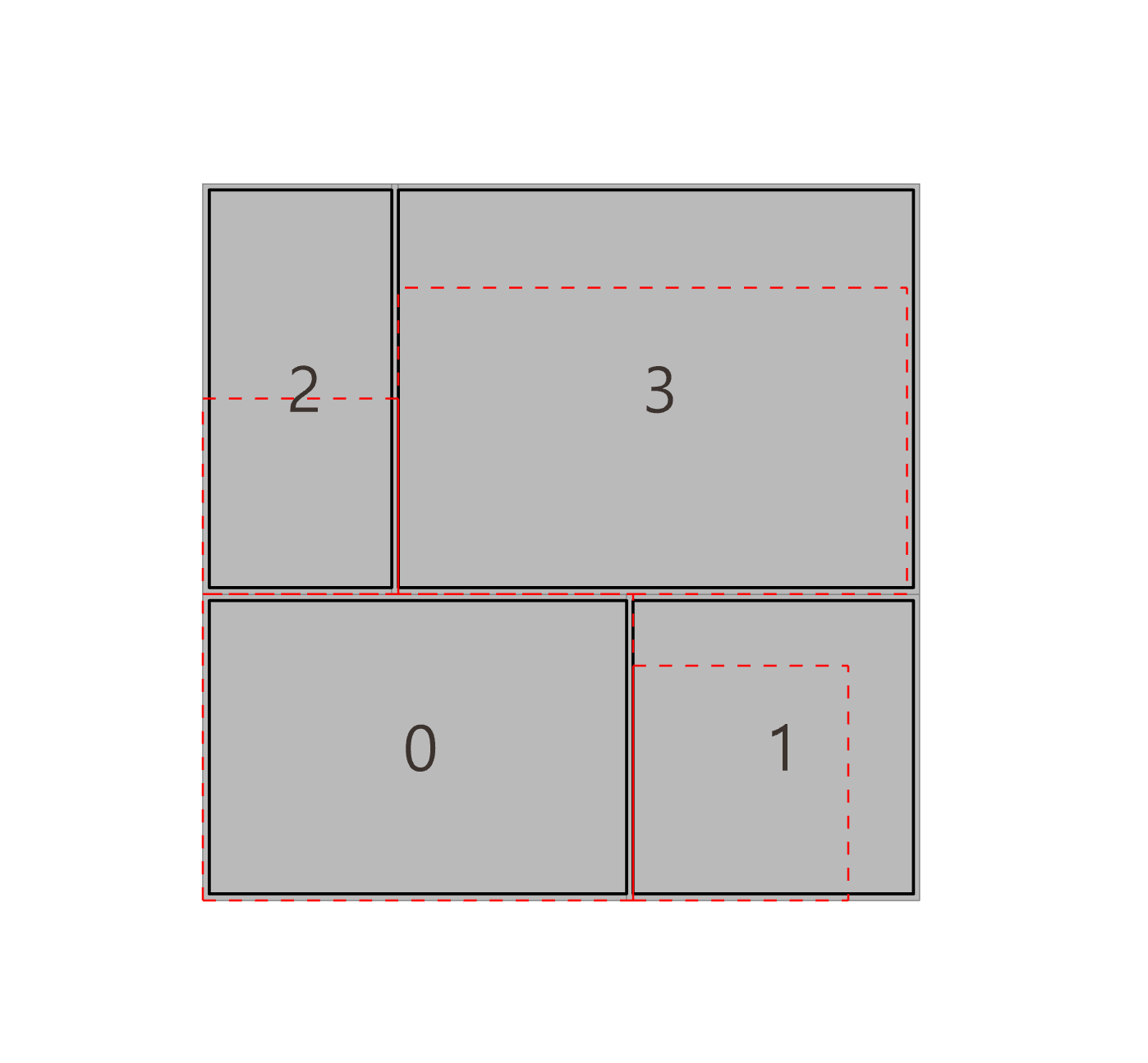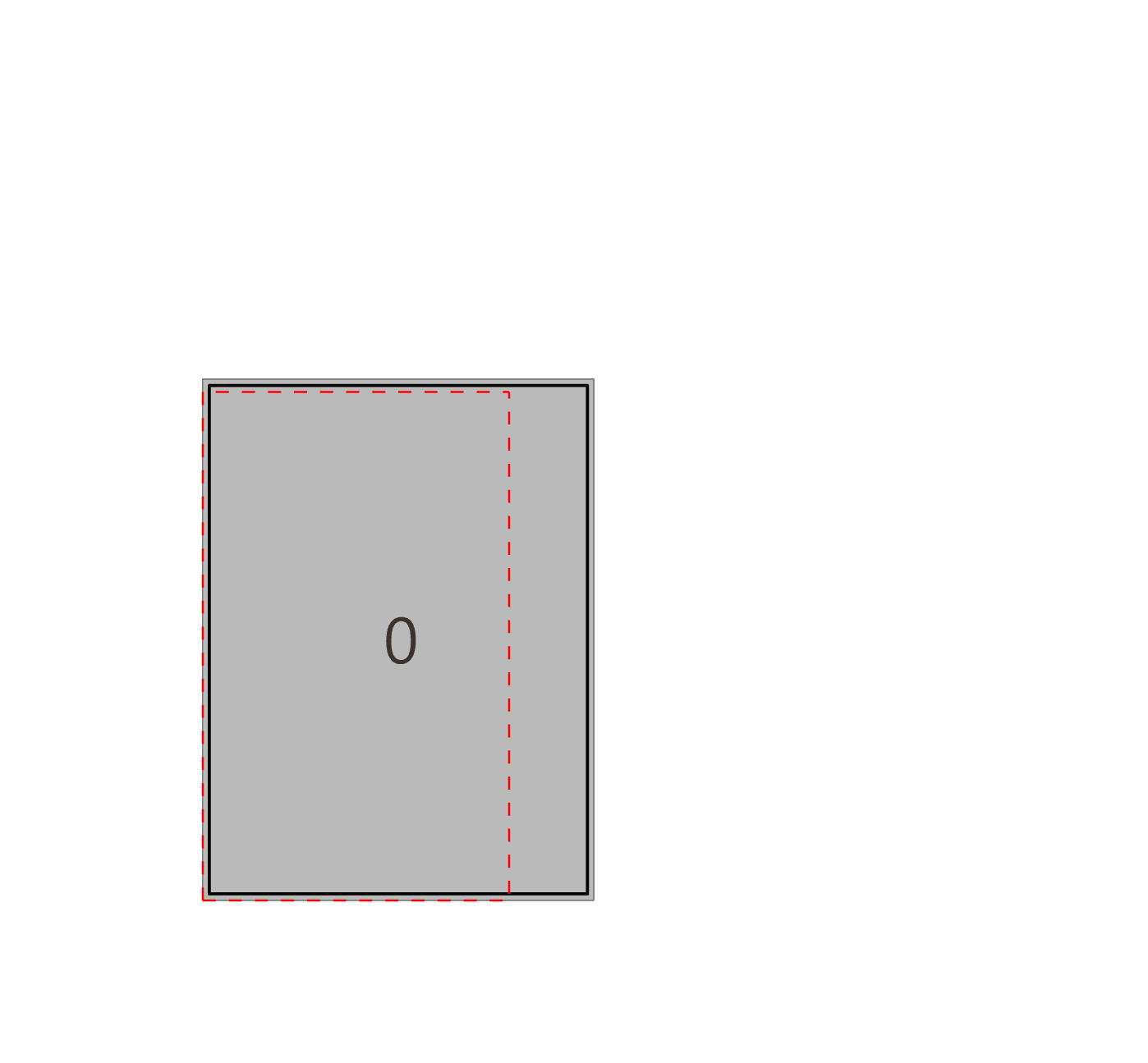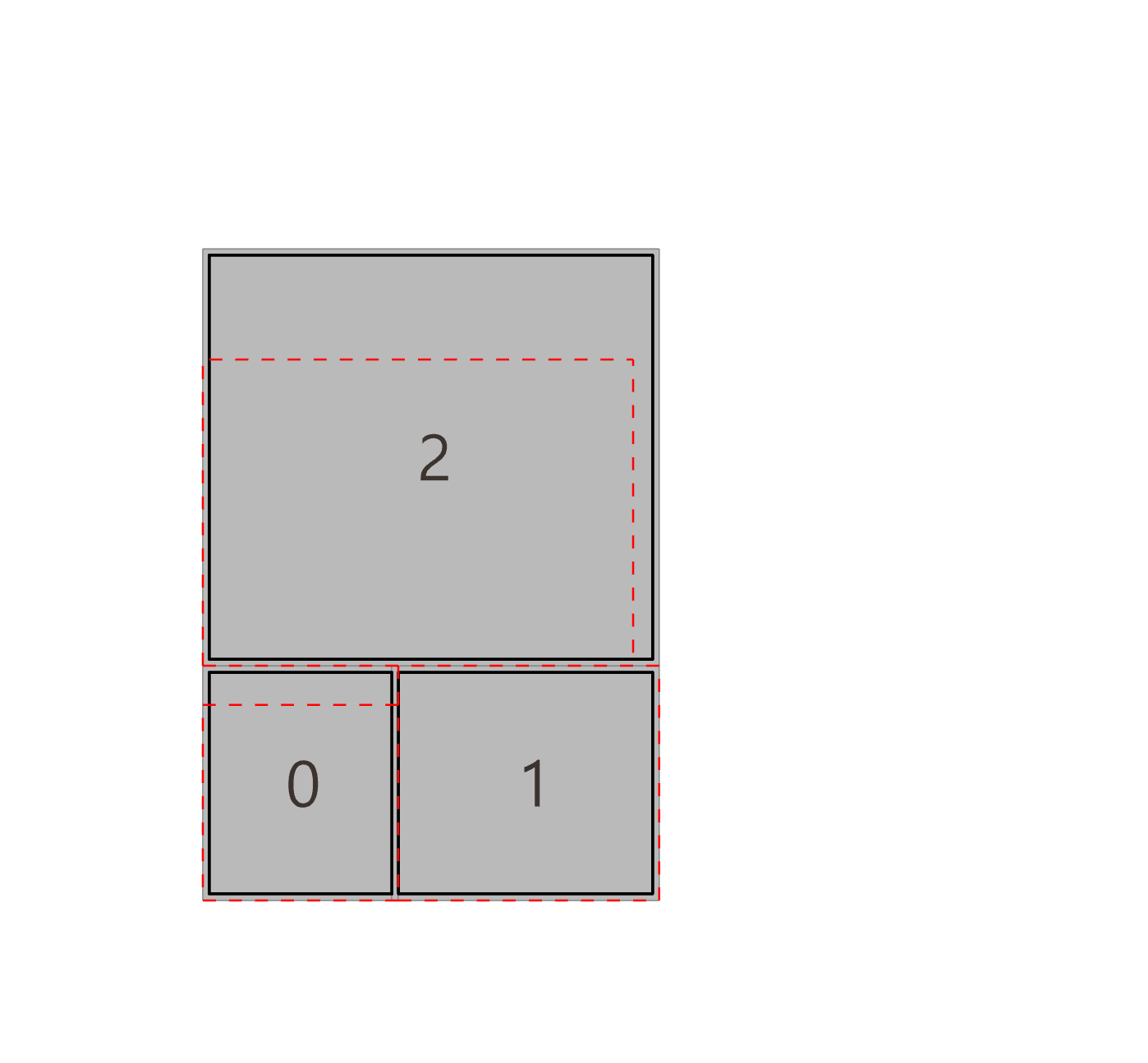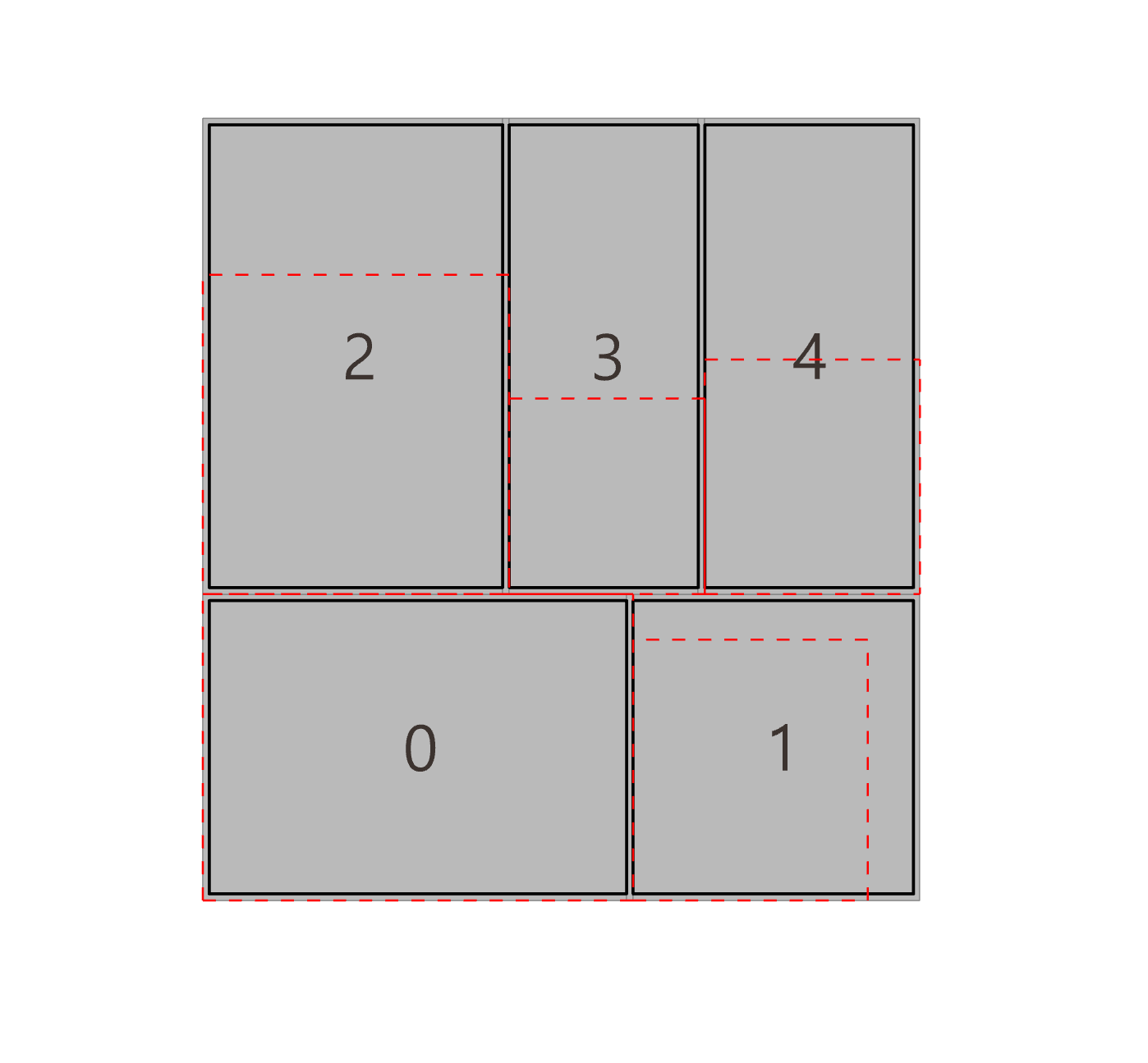

- 최적화 알고리즘
- LLM이 제안한 파라미터 조합(예: 창문을 50%만 private cell에 배정)에 따라 평면안을 대량으로 만든 뒤, 각 후보를 평가해 점수가 높은 상위안을 뽑아낸다.
- 영역 간 인접(그래프 구조), 창문 활용 비율, 그리고 디자이너가 지정한 “협업 vs. 집중” 비중 등을 모두 고려해 총합 점수를 계산한다.

최종적으로, 상위 후보들 중 어떤 안이 고객 요구와 디자인 철학에 가장 부합하는지를 LLM이 다시 판단하고 추천한다.
How Does AI Complement the Architect’s Role?
Automating Repetitive Sketching
과거엔 디자이너가 직접 스케치를 여러 번 그리며 가구를 옮겨보고, 복도 폭이나 창문 배치도 수십 번씩 바꿔봐야 했다. 이제 파라메트릭 모델이 그 ‘반복 스케치’ 과정을 자동화한다. 디자이너는 “몇 가지 핵심 가이드라인”을 LLM에게 말해주기만 하면, 모델이 다양한 평면안을 생성한다.
Consistently Applying Rules and Constraints
인접 행렬이나 버블 다이어그램을 통해 “어느 부서가 누구와 가까워야 하는지” 작성하던 과정을, 그래프와 최적화 알고리즘이 꼼꼼히 처리한다. - “IT 지원 부서는 모든 팀에 가까워야 한다” - “회의실은 입구 근처에 위치해야 한다” - “시끄러운 복사기 구역은 집중존과 거리를 둬야 한다” 이런 규칙을 일일이 손으로 세팅할 필요 없이, 알고리즘이 여러 레이아웃 중 인접도 점수가 높은 안을 골라준다.
Providing “Automatic Assistance” for the Designer’s Intuition
LLM은 “회사가 보수적 분위기”라거나, “직원들이 자연광을 선호한다” 같은 추상적 요구도 정량적 파라미터로 바꿔 준다. 예를 들어: - “private cell 75% 창문 차지” - “collaboration 영역은 전체의 25%만 배정” 이렇게 숫자로 변환되면, 최적화 알고리즘이 해당 조건을 만족하도록 레이아웃을 생성·평가한다. 디자이너는 이 결과 중 마음에 드는 것을 골라 인간적 감각(미학, 기업 문화)에 맞춰 다듬으면 된다.
Key Decisions LLM Makes
LLM은 단순히 “문장을 이해”하기만 하는 것이 아니다. 설계자가 입력한 프롬프트를 해석해, 다음과 같은 핵심 질문에 답한다.
- “사무실 영역을 몇 개로 나눠야 하는가?”
- 예: “private cell은 몇 개나 둘까?”
- 보수적인 사무실이라면 개인 업무실(Private Focus)을 창가에 빼곡히 배치, 협업을 중시하는 사무실이라면 open plan 위주 등으로 갈린다.
- “각 영역은 어떤 용도로 사용할 것인가?”
- 예: private cell을 개인 업무용 vs. 소규모 미팅용 중 어떤 방식으로 쓸지 결정.
- 예: private cell을 개인 업무용 vs. 소규모 미팅용 중 어떤 방식으로 쓸지 결정.
- “private cell을 창문으로 100% 채울지, 50%만 활용할지?”
- 회사의 운영 방식(미팅이 잦은지, 개인 업무가 중요한지)에 따라 LLM이 판단하고 수치화한다.
- 회사의 운영 방식(미팅이 잦은지, 개인 업무가 중요한지)에 따라 LLM이 판단하고 수치화한다.
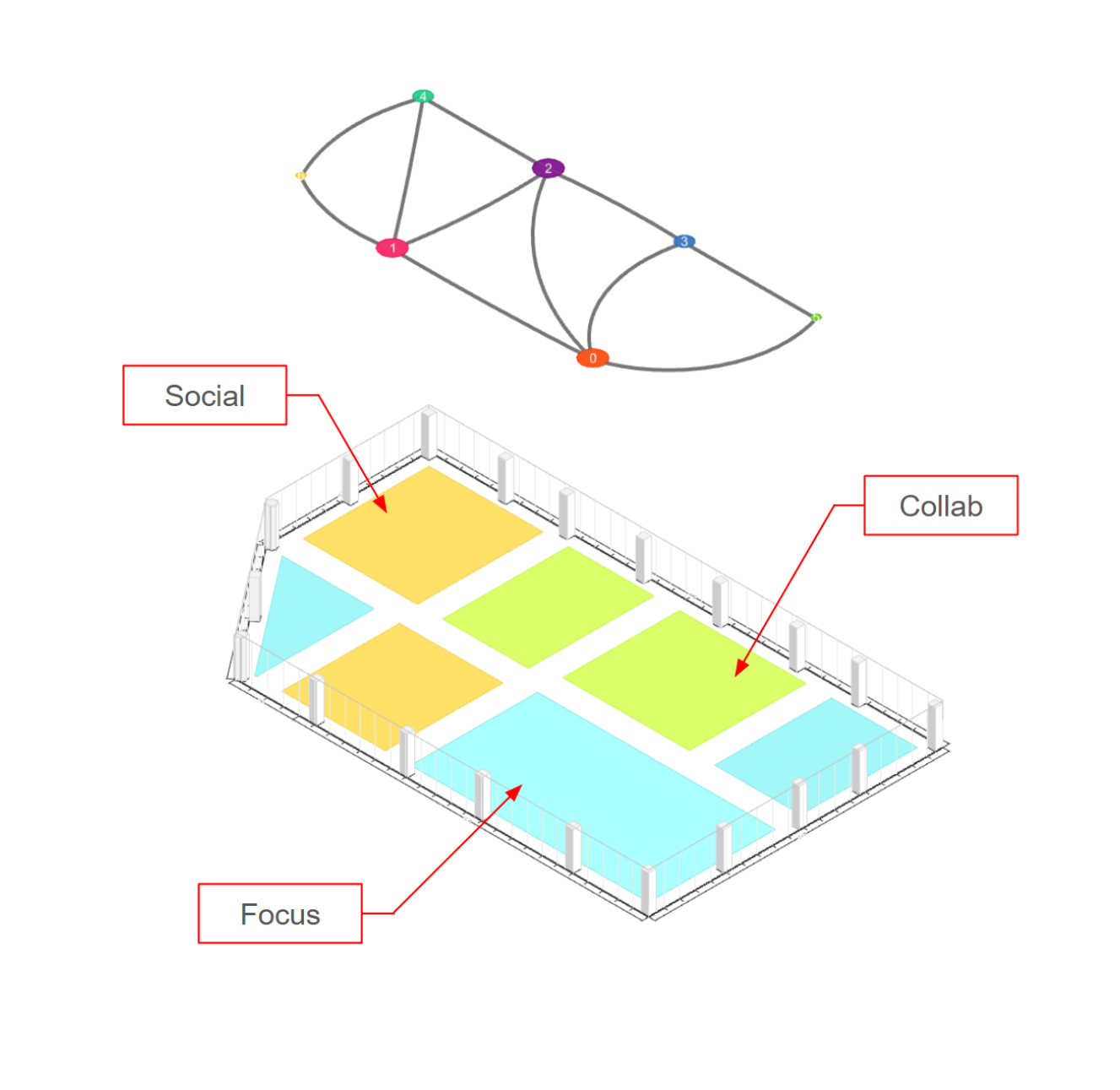
- “영역 간 인접 관계를 어떻게 설정할 것인가?”
- 포커스존과 소셜존이 붙어 있어도 될지, 아니면 분리해야 할지 등.
- 최적화 알고리즘은 이 인접 구조를 그래프로 만들어 점수를 매기며, LLM은 최종적으로 “어떤 그래프 구조가 가장 이상적인지” 선택한다.
Role of the System Prompt
- LLM이 오피스 레이아웃을 최적화할 때 따라야 할 기준을 정의한다.
- 사용자의 요구사항(공간 배치, 방향성, 개방성 등)을 LLM이 해석하고 적절한 설계 결정을 내릴 수 있도록 돕는다.
- 평가 기준과 점수를 통해 LLM이 최적의 설계안을 추천하도록 유도한다.
System Prompt Example
먼저 `RESPONSE_FORMAT`는 최종적으로 반환해야 할 JSON 구조에 관한 것으로, 이 구조는 `"type"`이 `"json_schema"`이며, `"json_schema"` 필드 안에서 `"name"`을 `"OfficeLayoutSchema"`로 두고, 그 안에서 `"schema"`라는 객체를 정의합니다.
이 `"schema"` 객체의 `"type"`은 `"object"`이고, `"properties"`로는 `candidate_index`(정수형)와 `reasoning`(문자열형)이 있으며, 이 두 프로퍼티는 반드시(`"required"`) 포함되어야 합니다.
즉, 최종 출력에는 최적의 디자인 후보를 뜻하는 `candidate_index`와 그 선택 이유를 담은 `reasoning` 필드가 포함되어야 합니다.
다음으로, 이 문서는 `SYSTEM_PROMPT` 전체에 대한 설명을 담고 있습니다.
해당 시스템 메시지는 오피스 레이아웃을 계획할 때 필요한 지침과 분석 방법을 상세히 제시합니다.
그 핵심적인 내용은, 사용자가 입력한 요구 사항을 분석해 최상의 디자인 후보를 선정하고, 그 결과를 `candidate_index` 형태로 반환하라는 것입니다.
특히 `target_focus`, `target_social`, `target_collab`, `adjacency_preferences` 같은 우선순위가 먼저 충족되어야 하며, 사용자가 방향(`direction`)에 관한 요구사항을 제시할 경우, 각 구역(zone)의 동·서·남·북 배치도 고려해야 한다는 점이 강조됩니다.
후보를 분석할 때 참고하는 `analysis_dict`에는 여러 항목이 있는데, 예컨대 각 구역(zone)의 면적 합을 의미하는 `total_area`, 구역 유형별 면적과 비율을 보여주는 `zone_area_by_type` 및 `zone_area_ratio_by_type`, 그리고 동·서·남·북 방향으로 구역이 어떻게 분포되는지 알려주는 `direction_distribution_by_type` 등이 있습니다.
또한 창문이 없는 벽이나 공간이 얼마나 되는지를 나타내는 `no_window_area_ratio`, 그리고 사적 공간과 개방형 공간을 비교하는 `private_vs_open_area` 역시 중요한 지표입니다.
이를 통해, 공간이 얼마나 개방적인지(폐쇄적 공간 대비 개방적 공간 비율), 단일적인지 혹은 다양한지, 기능이 고정되어 있는지 또는 유연한지, 단일 사용인지 복합 사용인지, 구역 간 경계가 경직되어 있는지 혹은 부드러운지 등을 평가할 수 있습니다.
이와 같은 평가를 위해서는 일곱 가지 지표를 살펴봐야 합니다. 그 일곱 가지 지표는 다음과 같습니다.
첫 번째로 `compute_diversity_ratio`는 공간이 특정 구역 유형에 치우치지 않고 얼마나 고르게 분포되는지를 측정해, 단일성(uniform)부터 다양성(diverse)까지 평가합니다.
두 번째로 `compute_open_space_ratio`는 개방형 구역과 사적 구역의 비중을 비교하며, 폐쇄형(close)부터 완전히 개방형(open)까지 나타냅니다.
세 번째인 `compute_soft_boundary_score`는 창문이나 벽면 개방 여부에 따른 공간 경계의 유연성을 평가해, 경직된 경계(rigid boundary)에서 부드러운 경계(soft boundary)까지의 범위를 살펴봅니다.
네 번째 `compute_transparency_score` 역시 창문 비율을 중점적으로 보되, 불투명(opaque)에서 투명(transparent)까지를 평가 기준으로 삼습니다.
다섯 번째인 `compute_flexibility_score`는 고정 기능(fixed function)에서 유연성(flexibility)에 이르기까지 얼마나 다양한 구역 유형이 의미 있는 비중을 차지하는지를 살피고, 여섯 번째 `compute_modular_score`는 적은 수의 대형 구역(단일 블록)으로 구성되었는지, 아니면 다수의 소형 구역(모듈형)으로 나뉘었는지를 통해 모놀리식(monolithic)부터 모듈식(modular)까지 평가합니다.
일곱 번째 `compute_mixed_use_score`는 사적 공간과 개방형 공간이 얼마나 균형적으로 섞여 있는지를 나타내며, 단일 사용(single-use)부터 복합 사용(mixed-use)에 이르는 스펙트럼을 확인합니다.
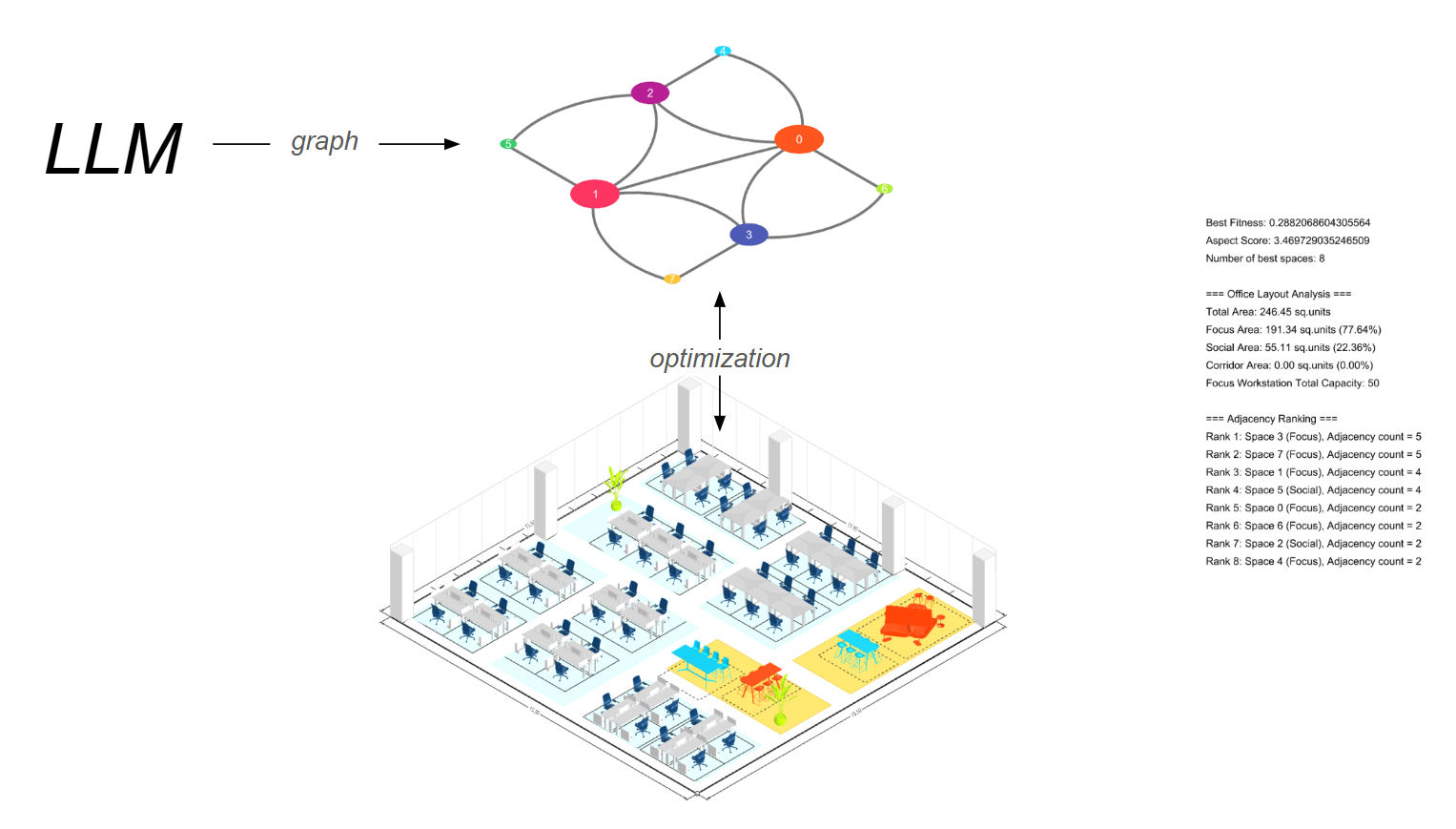
Parametric Model
LLM이 어떤 결정을 내렸다고 해서, 실제 평면이 즉시 단 하나만 나오는 것은 아니다. 파라메트릭 모델이 존재해야 다양한 조건을 조합해 여러 평면안을 생성할 수 있다.
- 건물 전체 윤곽과 기둥 위치: 입력으로 주어진다.
- 출입구, 창문, 복도 위치: 어떤 구역(포커스·소셜·프라이빗)이 어느 창문을 차지할지, 통로 폭은 얼마로 할지 등이 파라미터가 된다.
- 디자이너 희망 비율: 예컨대, 포커스 30%, 협업 50%, 소셜 20% 같은 값을 설정.
- LLM이 결정한 옵션: “창문의 25%만 private cell에 배정”이라던가, “프라이빗 미팅룸은 2개만 둔다” 같은 제한 사항도 반영.
즉, 파라메트릭 모델은 (규칙 + 변수) → 무수히 많은 레이아웃을 생성하는 ‘엔진’이 된다.
Optimization Algorithm
영역 간 배치가 끝나면, 시스템은 각 레이아웃 후보에 대해 일련의 지표를 계산한다. 예를 들어 아래 코드처럼, analysis_dict에 다양한 정보를 담는다:
analysis_dict = {
"total_area": total_area_all_zones,
"zone_area_by_type": zone_area_by_type,
"zone_area_ratio_by_type": zone_area_ratio_by_type,
"no_window_area_ratio": no_window_area_ratio,
"private_vs_open_area": {
"private_percent": private_area_pct,
"open_percent": open_area_pct,
},
"direction_score": direction_score,
}
candidate["analysis"] = analysis_dict
scores = compute_strategy_scores(analysis_dict, total_zones=total_zones_count)
candidate["strategy_scores"] = scores
candidate["direction_score"] = direction_score
이후 7가지 전략 점수(Strategy Scores)와 방향성 지표(Directional Analysis)를 계산해, 각 레이아웃이 얼마나 개방적이고, 다양하며, 기능적으로 유연한지, 그리고 태양광·뷰 등을 어떤 식으로 활용하고 있는지를 평가한다. 그리고 그 점수를 바탕으로 상위 후보를 선별한다.
Selecting Final Candidates and LLM Refinement
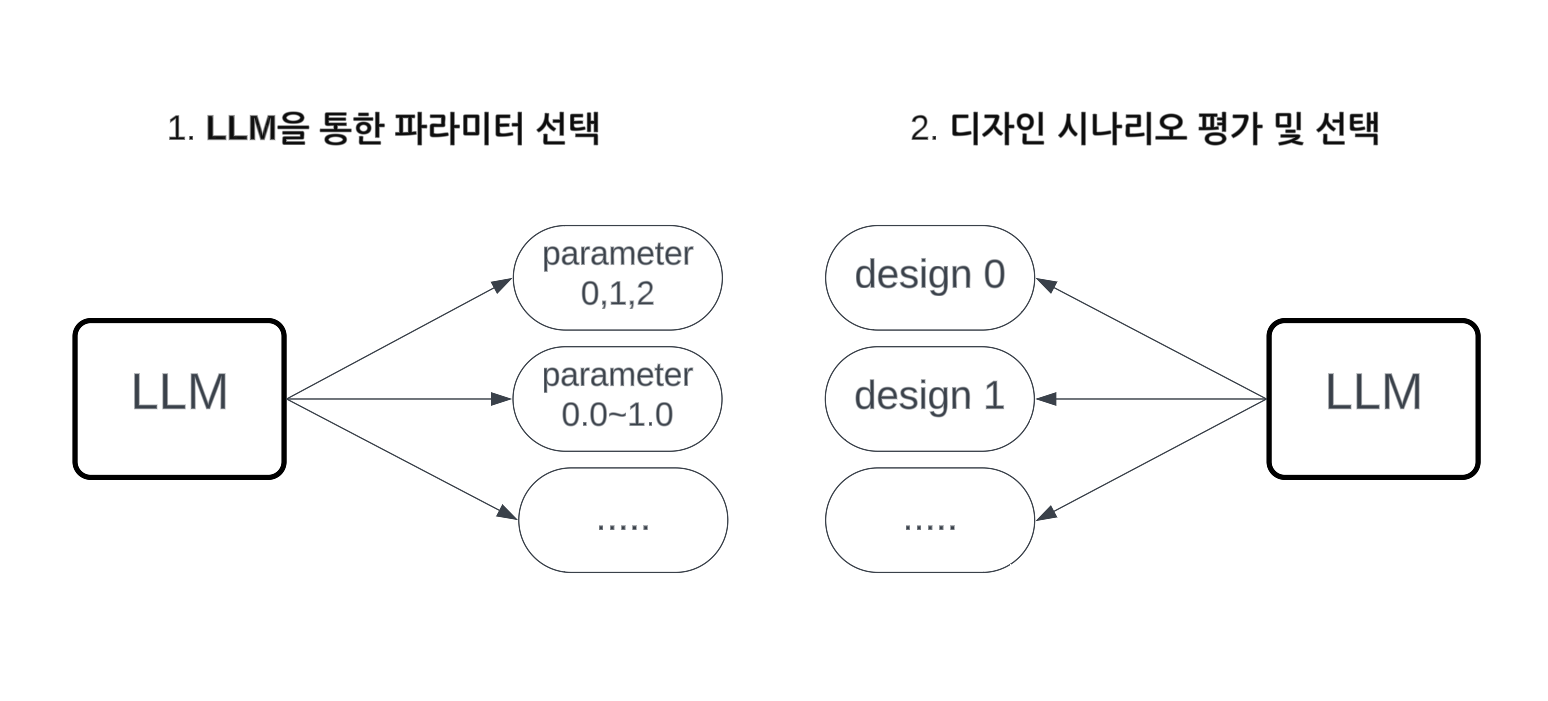
최적화 과정을 거치면 여러 ‘상위 후보’가 나온다. 이제 LLM이 다시 등장해, 사용자가 처음 제시했던 디자인 철학이나 선호도(예: “사적인 공간 선호, 협업 25%, 동향엔 소셜존 배치, 보수적 분위기”)와 가장 부합하는 후보를 최종 추천한다. 아래처럼 후보별 분석 정보를 한데 모은 뒤, LLM은 “candidate_index”와 “reasoning”을 JSON 형태로 반환한다.
all_candidates_data = []
for idx, candidate in enumerate(top_candidates):
candidate_data = {
"candidate_index": idx,
"analysis": candidate.get("analysis", {}),
"adjacency_info": candidate.get("adjacency_info", {}),
"strategy_scores": candidate.get("strategy_scores", {}),
"direction_score": candidate.get("direction_score", {}),
"focus_ratio": candidate.get("focus_ratio", None),
"social_ratio": candidate.get("social_ratio", None),
"collab_ratio": candidate.get("collab_ratio", None),
}
all_candidates_data.append(candidate_data)
Example: Parameter Suggestions and the Final Outcome
LLM은 이러한 System Prompt를 참고해, 사용자가 제시한 요구사항과 각종 설정 가이드를 토대로 JSON 응답을 구성할 수 있다. 예컨대:
{
"focus": 40,
"social": 30,
"collaboration": 30,
"member_type": "Collaborative",
"plan_type": "Mixed Type",
"atmosphere_type": "Dynamic & Collaborative",
"density_type": "Medium Density",
"cell_type": 1,
"private_cell_to_collab_ratio": 1,
"focus_preset_id": 2,
"split_density": 1,
"closed_or_opened_focus": 0,
"reasoning": "조용한 구역과 활발한 협업 공간이 절충되도록 40:30:30 비율로 설정했습니다. 창가는 절반 정도 private cell에 배정하고, 나머지는 협업 공간에 할애합니다..."
}
이렇게 파라미터가 결정되면, 최적화 알고리즘이 실제 평면안들을 쭉 만들어보고, 점수를 매긴 후 가장 이상적인 시안을 LLM이 최종적으로 골라준다.
Conclusion
LLM은 자연어 요구사항을 설계 전략과 규칙으로 전환해 주므로, 추상적인 아이디어나 기업 문화 같은 ‘말로만 전해지던 지식’을 직관적인 설계 파라미터로 구체화할 수 있다. 이렇게 정의된 조건을 파라메트릭 모델에 적용하면, 건물 구조와 면적, 창문, 가구 배치 같은 요소가 유기적으로 엮여 대규모 설계안을 자동으로 생성된다. 마지막으로 최적화 알고리즘은 이 거대한 후보군을 빠르게 탐색해, 인접성·공간 효율·방향성·유연성 등의 복합적인 조건을 최대한 만족하는 안들을 선별한다.
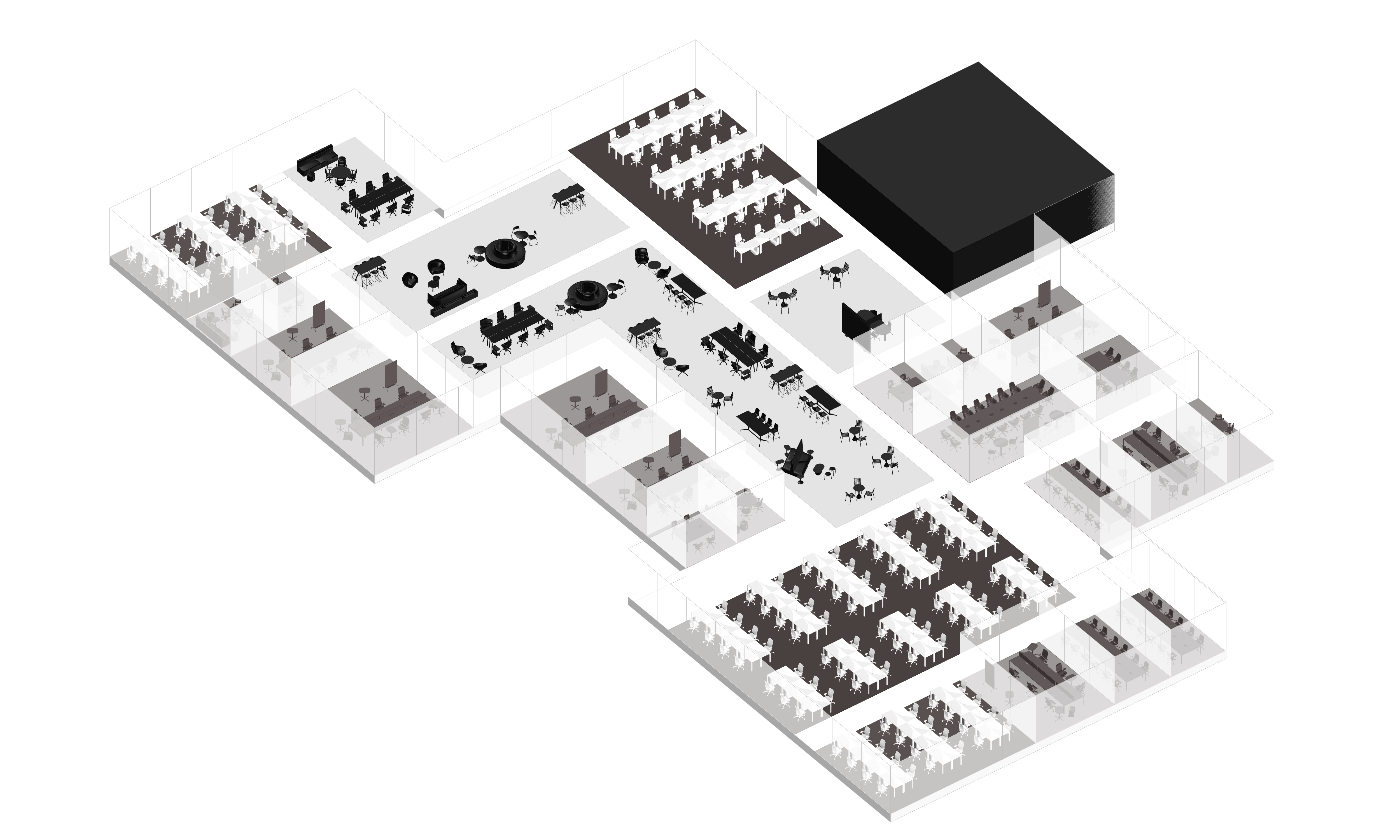
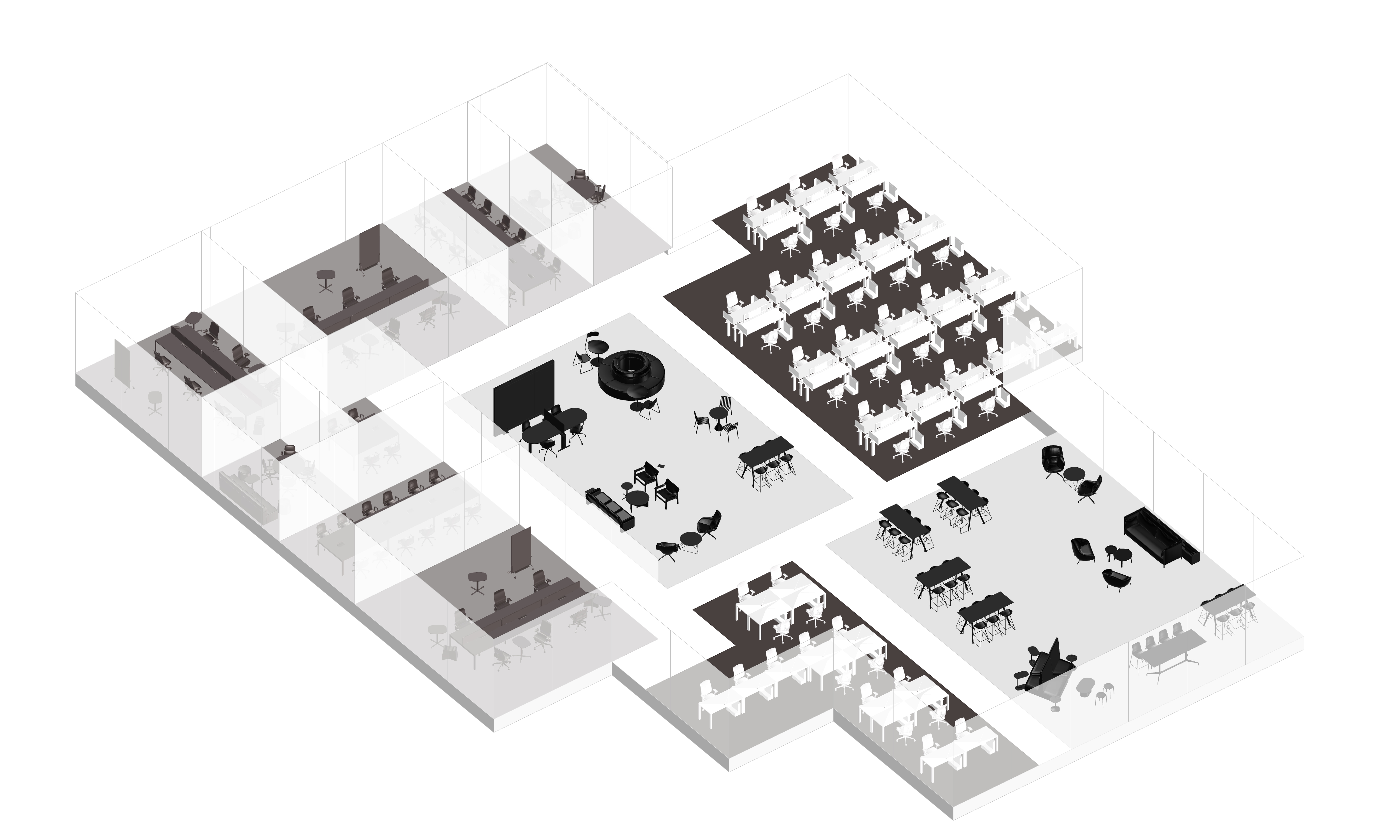
Result Examples
이 세 가지 핵심 요소(LLM, 파라메트릭 모델링, 최적화)를 활용함으로써, 디자이너는 이전보다 훨씬 빠르고 혁신적으로 오피스 레이아웃을 만들 수 있고, 창의적인 방향성과 전문적인 디자인 역량에 더 집중할 수 있을 것이다.